#7: Подбирайте URL под заголовки (если это имеет смысл)
Это не значит, что если ваша статья называется My Favorite 7 Bottles of Islay Whisky (and how one of them cost me my entire Lego collection) , то URL должен в точности повторять это. Что-то типа
randswhisky.com/my-favorite-7-islay-whiskies
или
randswhisky.com/blog/favorite-7-bottles-islay-whisky
или другие похожие примеры прекрасно подойдут. Цель этого, главным образом, — подготовить читателя к тому, что он найдёт на странице, и продолжить заголовком страницы.
![]()
Заголовок статьи выглядит так:
![]()
(правда, которую мы не признаём: алкоголь помогает здоровью)
Рэнд советует равняться на такой же уровень ясности и в ваших URL.
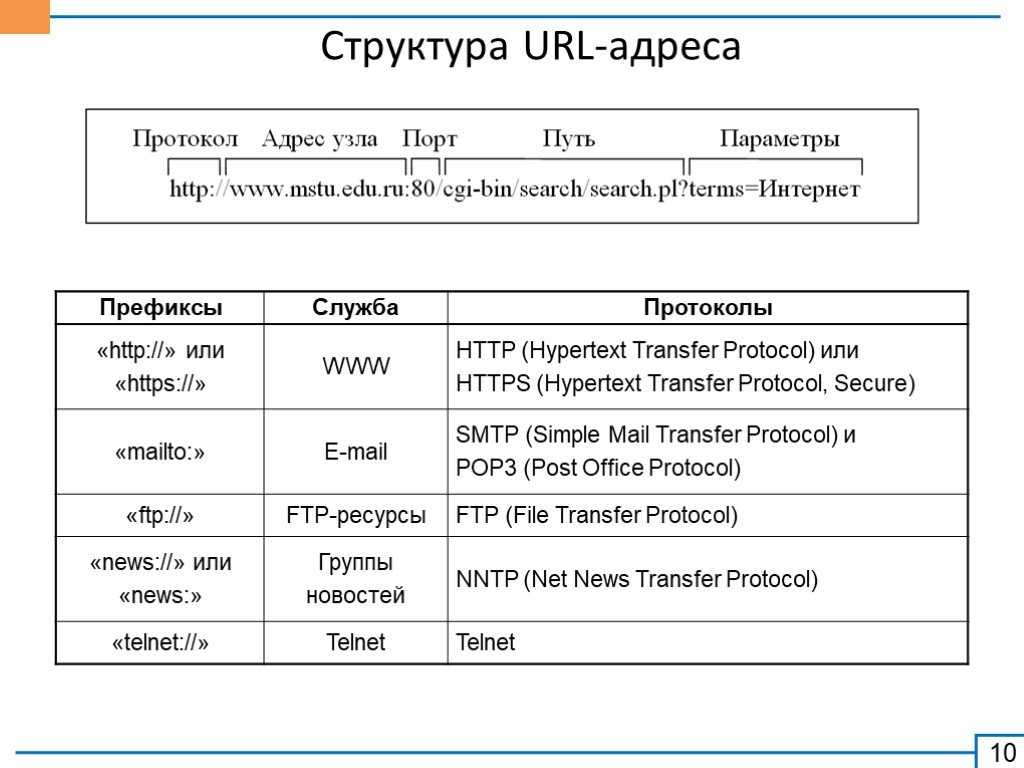
Форматы сообщений запроса/ответа
На следующем изображении вы можете увидеть схематично оформленный процесс отправки запроса клиентом, обработка и отправка ответа сервером.
![]()
Давайте посмотрим на структуру передаваемого сообщения через HTTP:
message = <start-line>
*(<message-header>)
CRLF
<start-line> = Request-Line | Status-Line
<message-header> = Field-Name ':' Field-Value
Между заголовком и телом сообщения должна обязательно присутствовать пустая строка. Заголовков может быть несколько:
Тело ответа может содержать полную информацию или её часть, если активирована соответствующая возможность (Transfer-Encoding: chunked). HTTP/1.1 также поддерживает заголовок Transfer-Encoding.
Общие заголовки
Вот несколько видов заголовков, которые используются как в запросах, так и в ответах:
general-header = Cache-Control
| Connection
| Date
| Pragma
| Trailer
| Transfer-Encoding
| Upgrade
| Via
| Warning
Что-то мы уже рассмотрели в этой статье, что-то подробней затронем во второй части.
Заголовок via используется в запросе типа TRACE, и обновляется всеми прокси-серверами.
Заголовок Pragma используется для перечисления собственных заголовков. К примеру, Pragma: no-cache — это то же самое, что Cache-Control: no-cache. Подробнее об этом поговорим во второй части.
Заголовок Date используется для хранения даты и времени запроса/ответа.
Заголовок Upgrade используется для изменения протокола.
Transfer-Encoding предназначается для разделения ответа на несколько фрагментов с помощью Transfer-Encoding: chunked. Это нововведение версии HTTP/1.1.







Заголовки сущностей
В заголовках сущностей передаётся мета-информация контента:
entity-header = Allow
| Content-Encoding
| Content-Language
| Content-Length
| Content-Location
| Content-MD5
| Content-Range
| Content-Type
| Expires
| Last-Modified
Все заголовки с префиксом Content- предоставляют информацию о структуре, кодировке и размере тела сообщения.
Заголовок Expires содержит время и дату истечения сущности. Значение “never expires” означает время + 1 код с текущего момента. Last-Modified содержит время и дату последнего изменения сущности.
С помощью данных заголовков, можно задать нужную для ваших задач информацию.
Виды URL и кодировка
УРЛы делятся на два вида:
- Абсолютный.
- Относительный.
Абсолютная ссылка – это URL в стандартной форме, содержащий протокол соединения, название домена и путь к файлу. Такие URL указывают на расположение искомого документа и применяются, когда нужно сослаться на сторонние веб-ресурсы. Например, https://imajor.ru/zarabotok/sayti/vse-sposobi – абсолютный УРЛ.
Для переходов в пределах одного сайта есть относительные ссылки, указывающие документ либо файл в отношении текущего местоположения файла. Допустим, у нас есть абсолютная ссылка http://www.site.com/images/icons.png. Из нее можно выделить 3 относительных адреса:
- ../images/icons.png – документ-относительный;
- /images/icons.png – корнеотражающий;
- //www.site.com/images/icons.png – протокол-относительный.
Шифрование
Любой URL вне зависимости от формата включает в себя символы из латинских букв, арабских цифр и специальных символов, о которых мы поговорим чуть позже. Также в УРЛах могут применяться посторонние символы, например, кириллица. Дело в том, что если пользователь перейдет на ресурс с URL, включающим набор кириллических букв, в адресной строке он отобразится корректно. Но скопировав ссылку и вставив ее в тот же Word, вместо них будет отображаться произвольный набор случайных символов.
URL обрабатывается следующим образом:
- Линк, состоящий из корректных символов,
кодируется в Юникод и образует читабельный URL-адрес. - В ссылке, где прописаны русские буквы, после
кодирования двухбайтовые данные заменяются на общепринятый шестнадцатеричный
код, который разделяется при помощи знака процента.
Возьмем URL
главной страницы русскоязычной Википедии. В адресной строке браузера она
выглядит следующим образом:
![]()
А так она изменится при копировании и вставке ссылки в
текстовый редактор:
В браузерах «прошлого поколения» присутствовало подобное шифрование URL. Сегодня же они отображают все символы в читабельном виде, а кодирование применяется лишь в случае внутреннего обмена ссылками. Однако копируя такие УРЛы в любой редактор, не способный изменять код в корректный вид, вы не сможете поделиться красивой и читабельной ссылкой.
Но и эта проблема решаема. Сегодня есть множество сервисов по кодированию/раскодированию URL, таких как design-sites.ru:
![]()
Пользователей русскоязычного интернета, конечно же, больше
привлекают кириллические тексты. Но использовать подобные URL-адреса для страниц вашего
веб-ресурса без особой необходимости я не рекомендую. Есть смысл прописывать
русскоязычные ссылки только при создании характерного сайта, где от них будет
зависеть привлечение целевой аудитории. А так латиница – это самый оптимальный
вариант.
Специальные символы
Кроме вышеупомянутых символов в URL иногда
указывают еще и спецсимволы:
- «?» – разделяет в строке запроса блок с передаваемыми данными;
- «=» – разделяет в параметре переменную от ее значения;
- «@» – вводится в регистрационных данных пользователя и в процессе передачи информации посредством протокола mailto;
- «&» – отделяет друг от друга передаваемые данные;
- «:» – отделяет протокол от всех других символов в ссылке;
- «#» – указывается в конце ссылки, перемещает читателя к определенному фрагменту документа.
Чем так вреден дублированный контент?
Задваивание, как и спам-ссылки влекут за собой жесткие санкции. Да и вообще, плохое сканирование может привести к де-актуализации вашего сайта. На идентификацию сети Google выделяет значительные средства, чтобы все обновления и изменения отображались в результатах поиска. Есть специальный ограниченный краулинговый бюджет, который выделяется каждому сайту. Сумма этого бюджета будет зависеть от того, как часто вы проводите обновления, насколько посещаема ваша платформа, какова ее структура, сложность и объём.
Но если вы клонировали страницу, программа будет делить бюджет на четыре части, и вам просто хватит средств для полноценной работы. Как результат, многие изменения и новинки просто не будут идентифицироваться, а будет светиться старая информация. Хуже того, при регулярном выявлении задвоенных страниц ваш бюджет, как и частота посещений, могут быть уменьшены.
Что застраховать себя от подобных неприятностей, стоит выбирать более сложный линк. С абсолютными URL таких сюрпризов не возникает. Система поиска видит только оригинальную версию сайта, не отвлекаясь на дубликаты, поэтому в данном случае будет видна только обновленная информация.
![Что такое url адрес: структура и значение для seo [инфографика]](https://radio-sgom.ru/wp-content/uploads/3/4/0/34056ac1f7fb505aabb9a2f5004c5ec0.jpeg)







Что такое хэш (hash) ссылки
Иногда в структуре УРЛ можно встретить ещё одну составляющую: хэш ссылку. Располагается данный элемент после значка # и называется якорь. Основное назначение якоря:
- в html документе такие ссылки или якоря используются, чтобы обеспечить быстрый возврат в определенную точку кода;
- также якоря прописывают в гиперссылках, чтобы пользователь автоматически попадал в нужную ему точку страницы или документа (в другом случае страница откроется с начала документа);
- существует определенная хитрость: если место якоря в ссылке оставить без символов, то страница открывается в самом начале. Этот прием используют для создания кнопки «Наверх».
Таким образом, якорь позволяет быстро
ориентироваться по документу, как пользователю, так и веб дизайнеру.
Краткое руководство по URL-адресам и путям
Чтобы полностью понять адреса ссылок, вам нужно понять несколько вещей про URL-адреса и пути к файлам. Этот раздел даст вам информацию, необходимую для достижения этой цели.
URL-адрес (Uniform Resource Locator, или единый указатель ресурса, но так его никто не называет) — это просто строка текста, которая определяет, где что-то находится в Интернете. Например, домашняя страница Mozilla находится по адресу .
URL-адреса используют пути для поиска файлов. Пути указывают, где в файловой системе находится файл, который вас интересует. Давайте рассмотрим простой пример структуры каталогов (смотрите каталог creating-hyperlinks.)
Корень структуры — каталог . При работе на локальном веб-сайте у вас будет один каталог, в который входит весь сайт. В корне у нас есть два файла — и . На настоящем веб-сайте был бы нашей домашней, или лендинг-страницей (веб-страницей, которая служит точкой входа для веб-сайта или определённого раздела веб-сайта).
В корне есть ещё два каталога — и . У каждого из них есть один файл внутри — и , соответственно
Обратите внимание на то, что вы можете довольно успешно иметь два файла в одном проекте, пока они находятся в разных местах файловой системы. Многие веб-сайты так делают. Второй , возможно, будет главной лендинг-страницей для связанной с проектом информации
-
Тот же каталог: Если вы хотите подключить ссылку внутри (верхний уровень ), указывающую на , вам просто нужно указать имя файла, на который вы хотите установить ссылку, так как он находится в том же каталоге, что и текущий файл. Таким образом, URL-адрес, который вы используете — :
-
Перемещение вниз в подкаталоги: Если вы хотите подключить ссылку внутри (верхний уровень , вам нужно спуститься ниже в директории перед тем, как указать файл, который вы хотите. Это делается путём указания имени каталога, после которого идёт слеш и затем имя файла. Итак, URL-адрес, который вы используете — :
-
Перемещение обратно в родительские каталоги: Если вы хотите подключить ссылку внутри , указывающую на , вам нужно будет подняться на уровень каталога, затем спустится в каталог . «Подняться вверх на уровень каталога» обозначается двумя точками — — так, URL-адрес, который вы используете :
Примечание: вы можете объединить несколько экземпляров этих функций в сложные URL-адреса, если необходимо, например: .
Можно ссылаться на определённую часть документа HTML (известную как фрагмент документа), а не только на верхнюю часть документа. Для этого вам сначала нужно назначить атрибут элементу, с которым вы хотите связаться. Обычно имеет смысл ссылаться на определённый заголовок, поэтому это выглядит примерно так:
Затем, чтобы связаться с этим конкретным , вы должны включить его в конец URL-адреса, которому предшествует знак решётки, например:
Вы даже можете использовать ссылку на фрагмент документа отдельно для ссылки на другую часть того же документа:
Два понятия, с которыми вы столкнётесь в Интернете, — это абсолютный URL и относительный URL
- Абсолютный URL
- Указывает на местоположение, определяемое его абсолютным местоположением в Интернете, включая протокол и доменное имя. Например, если страница загружается в каталог, называемый , который находится внутри корня веб-сервера, а домен веб-сайта — , страница будет доступна по адресу (или даже просто ), так как большинство веб-серверов просто ищет целевую страницу, такую как , для загрузки, если он не указан в URL-адресе.).
Абсолютный URL всегда будет указывать на одно и то же местоположение, независимо от того, где он используется.
- Относительный URL
- Указывает расположение относительно файла, с которого вы связываетесь, это больше похоже на случай, который мы рассматривали в предыдущей секции. Для примера, если мы хотим указать со страницы на PDF файл, находящийся в той же директории, наш URL может быть просто названием файла — — никакой дополнительной информации не требуется. Если PDF расположен в поддиректории внутри каталога , относительная ссылка будет (аналогичный абсолютный URL был бы .).
Относительный URL будет указывать на различные места, в зависимости от того, где находится файл, в котором он используется, — например, если мы переместим наш файл из каталога в корневой каталог веб-сервера (верхний уровень, не в директорию) , то относительный URL будет вести на , а не на .
Советуем вам основательно разобраться в этой теме!
https://
Чтобы не вдаваться в технические подробности, скажем просто: это защищённый вариант соединения http://
Актуален там, где речь идёт о хранении важной информации о пользователях. Например, если сайт связан с покупкой/оплатой или паспортными данными
Как пример – тот же Яндекс.
Но как именно такой протокол помогает уберечь пользователя? У него есть несколько степеней защиты, каждый из которых предоставляется владельцу сайта после предъявления личных данных. В каждом браузере, в адресной строке (место, где пишется URL-адрес), есть небольшая картинка.







При обычном (http), или защищённом первой степени (https) она остаётся неприметной:
![]()
Если же владелец ресурса подтвердил достаточно данных, мы увидим зелёный значок, а иногда и название компании.
![]()
Таким образом, находясь на таком «зелёном» сайте можно не беспокоиться о том, что вы каким-либо образом могли попасть на сайт мошенников, замаскированный под официальный.
Рендеринг страниц
- Путём перебора DOM-узлов и вычисления для каждого узла значений CSS-стилей создаётся «Дерево рендера» (Render Tree или Frame Tree).
- Вычисляется предпочтительная ширина каждого узла в нижней части дерева — для этого суммируются значения предпочтительной ширины дочерних узлов, а также горизонтальные поля, границы и отступы узлов.
- Вычисляется реальная ширина каждого узла сверху-вниз (доступная ширина каждого узла выделяется его потомкам).
- Вычисляется высота каждого узла снизу-вверх — для этого применяется перенос текста и суммируются значения полей, высоты, отступов и границ потомков.
- Вычисляются координаты каждого узла (с использованием ранее полученной информации).
- Если элементы плавающие или спозиционированы абсолютно или относительно, предпринимаются более сложные действия. Более подробно они описаны здесь и здесь.
- Создаются слои для описания того, какие части страницы можно анимировать без необходимости повторного растрирования. Каждый объект (фрейма или рендера) присваивается слою.
- Для каждого слоя на странице выделяются текстуры.
- Объекты (рендеры/фреймы) каждого слоя перебираются и для соответствующих слоёв выполняются команды отрисовки. Растрирование может осуществляться процессором или возможна отрисовка на графическом процессоре (GPU) через D2D/SkiaGL.
- Все вышеперечисленные шаги могут требовать повторного использования значений, сохранённых с последнего рендеринга страницы, такая инкрементальная работа требует меньше затрат.
- Слои страницы отправляются процессу-компоновщику, где они комбинируются со слоями для другого видимого контента (интерфейс браузера, iframe-элементы, addon-панели).
- Вычисляются финальные позиции слоёв и через Direct3D/OpenGL отдаются композитные команды. Командные буферы GPU освобождаются для асинхронного рендеринга и фрейм отправляется для отображения на экран.
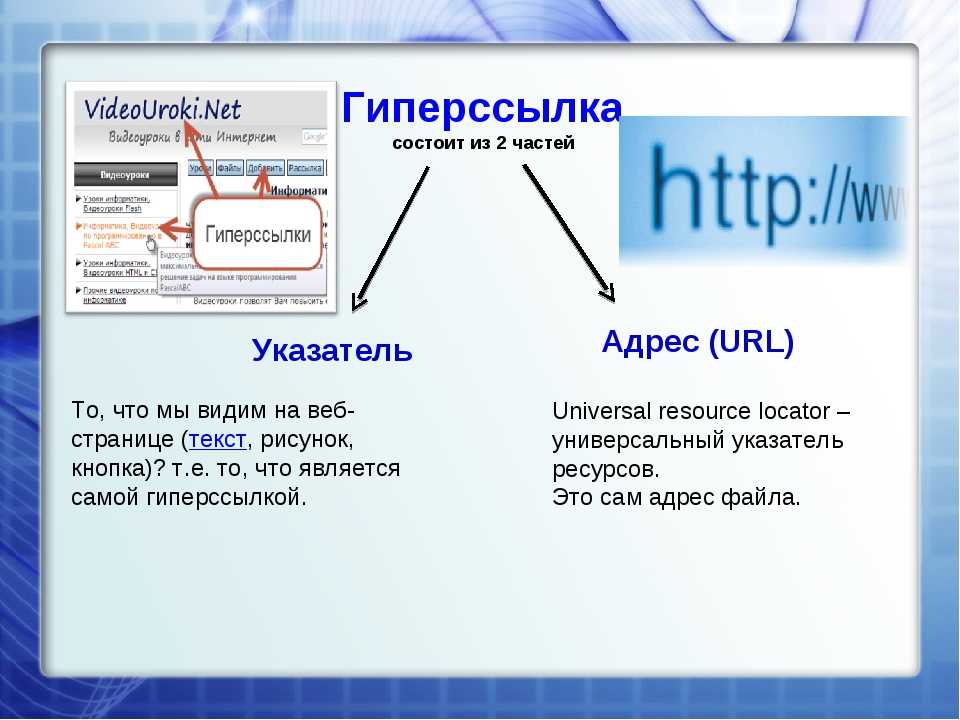
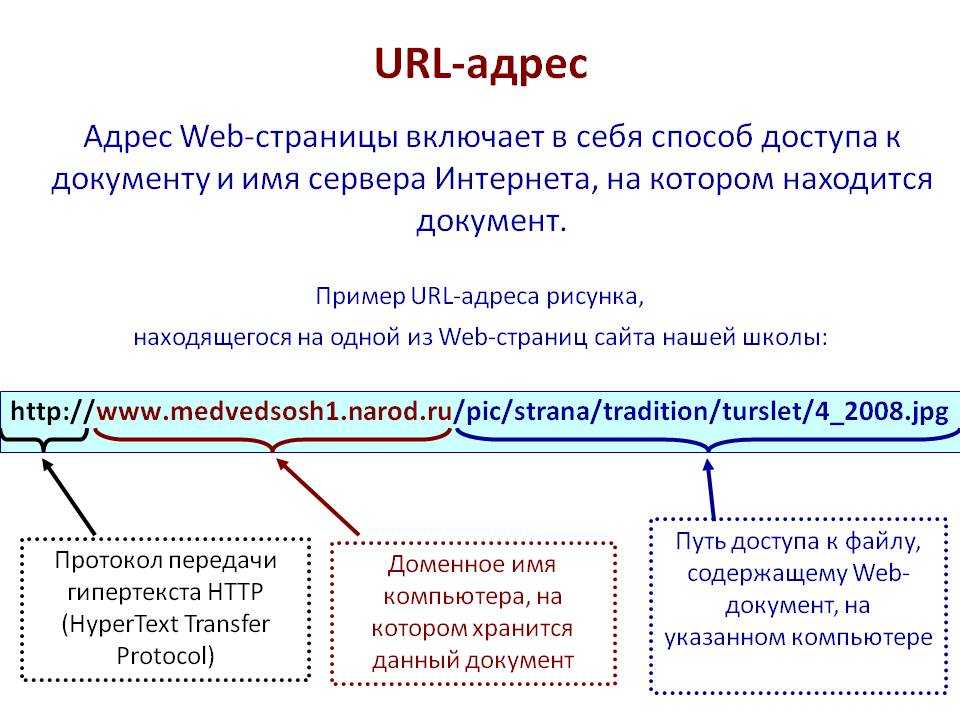
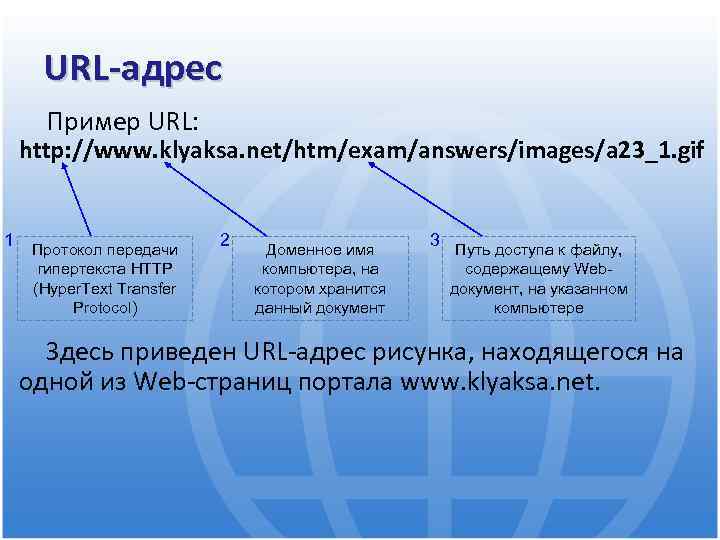
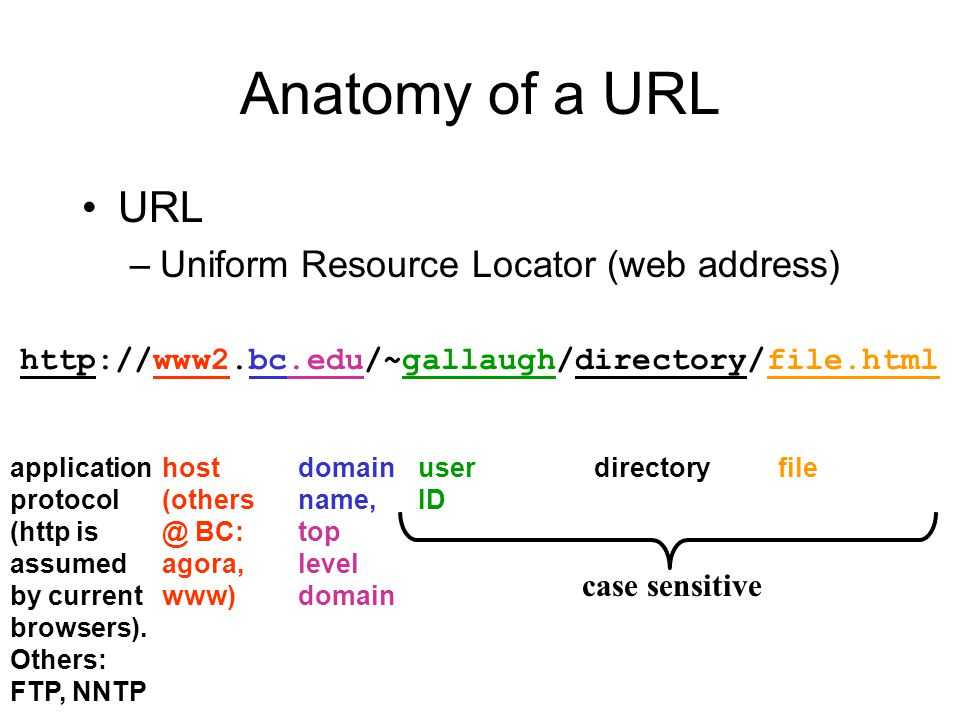
Из чего состоит URL страницы?
Как узнать URL адрес страницы? Просто посмотрите на адресную строку в своем браузере, к примеру, адрес этой статьи — https://moisovety.com/chto-takoe-url-sajta-sostavlyayushhie-istoriya-i-interesnye-fakty. Мы возьмем его в качестве примера, чтобы рассмотреть, из чего состоит URL.
Протоколы: FTP, HTTP и HTTPS и HTTP/2.0
Transfer Protocol, он же протокол передачи гипертекста. В основе протоколов лежит технология «клиент-сервер»: клиент инициирует соединение и посылает запрос, а сервер ожидает это соединение для получения запроса, выполняет определенный алгоритм действий и возвращает обратно сообщение с запрашиваемым результатом пользователю.
Протоколы разрабатываются компанией Internet Engineering Task Force, сокращенно IETF. На самом деле их достаточно много, однако мы приведем 4 ключевых варианта:
-
ftp:// —File Transfer Protocol. Это один из самых старых прикладных протоколов, который появился еще в 1971 году. В наше время сталкиваться с ним приходится очень редко.
-
http:// — Hypertext Transfer Protocol. Появился в 1999 году, по умолчанию сейчас действует версия http 1.1. В этой версии клиент (пользователь) должен посылать информацию про имя хоста, что упростило организацию хостинга. Таким протоколом, в частности, пользуются Мои Советы.
-
https:// – HyperText Transfer Protocol Secure (добавляется слово «защищенный»). Технология используется для защиты конфиденциальности и информационной безопасности в Сети. По сути, это обычный http, который пропускается через шифровальные механизмы SSL и TLS.
-
http/2.0 — вторая версия стандартного протокола, которая только планируется к внедрению. Полагается, что он сможет улучшить качество связи в 10 (!) раз. В технологии будет изменено сжатие http-заголовков, система приоритетов, внедрена система Server push и оптимизирован еще ряд моментов.
Первая часть ссылки URL указывает, какой протокол будет использован для доставки информации от сервера к пользователю. Он всегда размещается впереди доменного имени и отделяется «://».
Доменное имя
Доменное имя — это текстовое представление IP-адреса, которое используется для идентификации конкретной веб-странички. Доменное имя пишется после символов ://.
Любопытно, что на современном сленге доменное имя часто называют «мордой» ![]()
Директория или Путь
С помощью директории организовывается структура сайта, ее можно увидеть после косой черты (слеша). Раньше активно использовался метод «хлебных крошек» — то есть создания навигационной цепочки, которая вела пользователя от корневого каталога (главной страницы сайта) до конкретной статьи или товара. На примере Розетки это выглядит это так:![]()
Навигационная цепочка влияет на ссылку страницы.
Однако с 2012 консорциум WWW (он же консорциум Всемирной паутины, W3C) настойчиво советует устранять из адреса веб-страницы лишние элементы (каталоги, разделы и подразделы), оставляя только доменное имя и страницу. К примеру, так реализован этот аспект в Comfy. На странице вы можете увидеть путь, однако на URL это не отображается — он содержит только доменное имя сайта и конечный раздел:![]()
Имя файла/страницы, параметр и якоря
Виды страниц:
- название страницы.html или .htm.
- название страницы.php или .asp.
- / — просто слеш, по умолчанию означает, что это директория.
- Отсутствие слеша в конце URL также возможно, однако это не лучший вариант для сайта (замедляется сканирование и уменьшается краулинговый бюджет).
В конце УРЛ может размещаться специальный якорь, или же анкор-метка (в оригинале Named Anchor). Оформляется она с помощью символа #. На нашем сайте используются якоря в оглавлении статьи: мы установили их в подзаголовки текста, а ссылки в пунктах оглавления дают доступ к ним. Нажимая на подзаголовок в оглавлении, вы перемещаетесь к определенному месту в теле самой статьи.






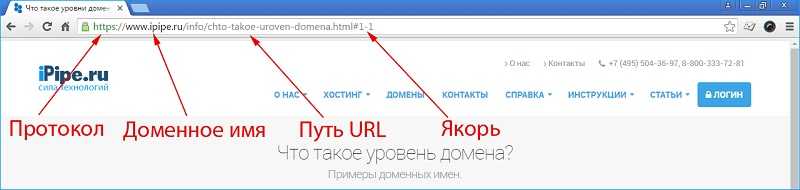
Для примера:
Общее правило: при отсутствии анкор-метки все браузеры стабильно отправляют посетителя, то есть вас, в самое начало страницы.
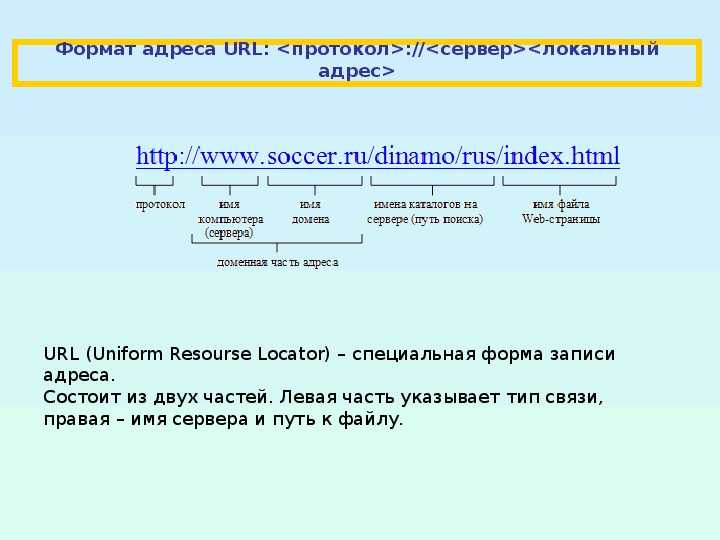
Из чего состоит веб-адрес
Чтобы унифицировать все веб-адреса создан специальный стандарт, благодаря которому у всех урлов существует простой и понятный путь к хранению файла.
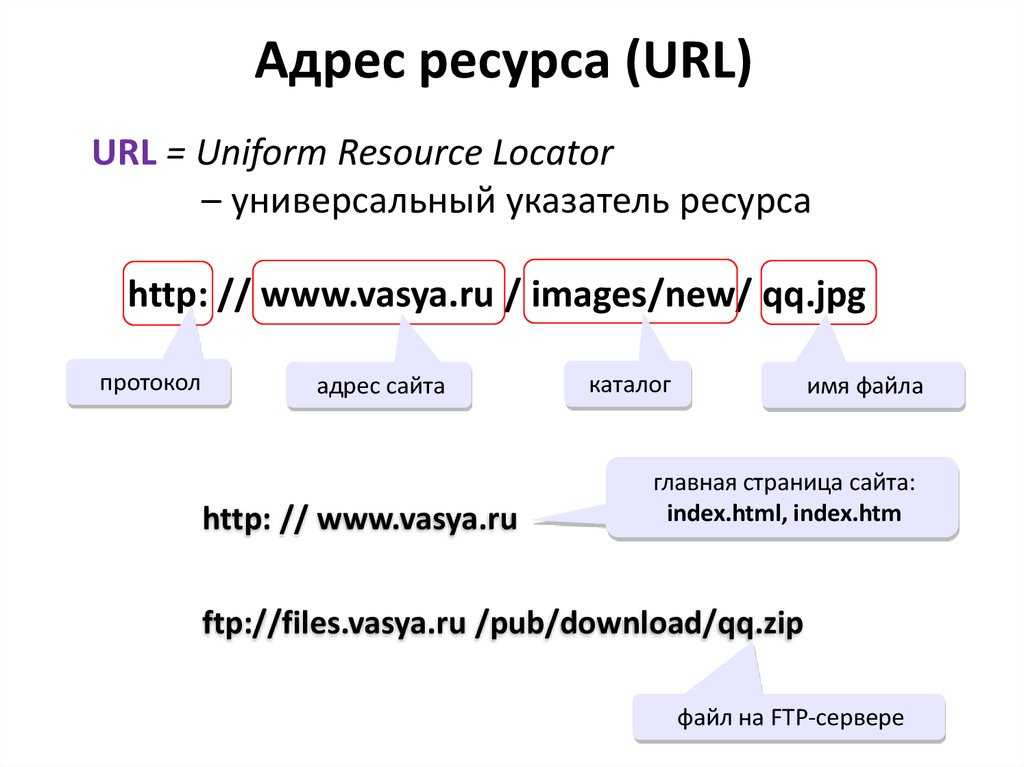
Символы, которые мы видим в адресной строке и есть URL-адрес. Структура любого URL выглядит так:
В структуре обязательно используется <схема> и <хост>, остальные части необязательные.
Схема — протокол передачи данных. Существует огромное количество протоколов, но чаще всего это:
- FTP:// (File Transfer Protocol)предоставляет удаленный доступ к хостингу, передаче данных с сервера на устройство пользователя и наоборот;
- HTTP:// (Hyper Text Transfer Protocol) — протокол передачи гипертекста предназначен для транспортировки произвольных данных (изначально, в формате HTML).
HTTPS:// (Hyper Text Transfer Protocol Secure) — HTTP протокол, для повышения безопасности работающий с помощью транспортных механизмов SSL и TLS.
Логин: пароль — имя и пароль для входа в учетную запись. Для HTTP/HTTPS-протоколов не используется. Обычно применяется для протокола FTP (ftp://name:password@qwerty.ua).
Хост — доменное имя сайта. Зачастую используется название бренда, например netpeak.ua. Также может использоваться IP-адрес (172.217.168.195), но сейчас его применяют очень редко, так как IP запомнить сложнее.
Порт — составная часть веб-адреса, числовой идентификатор программы или процесса, предоставляющий возможность доступа к ресурсам на указанном IP-адресе. Например, за http-сервером закреплен 80 порт, а за https — 443. То есть для соединения с веб-сервером нам необходимо знать IP-адрес компьютера и его порт. В свою очередь, чтобы веб-сервер мог передать данные на наш компьютер, ему необходимо предоставить IP и порт нашего компьютера, чтобы принять ответ от сервера, а после обработать данные.
URL-путь — это адрес, где расположен ресурс или файл на веб-сервере. К примеру, по адресу https://netpeak.ua/services/seo/ можно понять, что услуги категории «SEO» расположены в директории «Услуги».
Параметры — специальные данные, которые браузер сообщает веб-серверу. Как правило, параметры указываются после знака «?» и разделяются «&». Всё, что идет до вопросительного — основной URL, после — дополнительные параметры. https://site.com/cat332t1.html?sort_direction=desc&sort_by=price_desc
Якорь — вид закладки на странице, которая направляет пользователя на определенную часть страницы (помеченный фрагмент кода). Реализовывается с помощью символа «#»: https://en.wikipedia.org/wiki/URL#Syntax.
Общая информация
URL адрес – это адрес какого-либо ресурса в интернете.
Под понятием «ресурс» в прошлом предложении имеется в виду сайт, изображение, документ или что-либо еще, что только может находиться в интернете на каком-то удаленном сервере.
Для справки: сервер – это отдаленное хранилище информации. Его можно сравнить со шкафом. Вы можете положить рубашку в шкаф, а когда она вам понадобится, взять его. Точно так же информация может храниться на сервере и быть взятой из него, только если это потребуется пользователю.
Теперь вернемся к URL адресам. Собственно, этот адрес показывает, где можно найти тот или иной ресурс.
К примеру, если это URL какой-то страницы в интернете, чтобы ее отобразить, нужно найти ее исходный файл, то есть код.
URL адрес и показывает, в каком «шкафу» находится «рубашка» в виде сайта.
Точно также с URL изображения или документы – эти файлы должны где-то находиться, а точнее, на сервере. URL показывает адрес этого сервера.






![Что такое url адрес: структура и значение для seo [инфографика]](https://radio-sgom.ru/wp-content/uploads/5/9/f/59fd8d3630614c5a7ca008a4b9921725.jpeg)
Он имеет свою уникальную структуру, о которой речь пойдет далее.
Пока что можно сказать, что URL расшифровывается как Universal Resource Locator, то есть универсальный указатель ресурса. А если по-русски, то это адрес сервера, на котором находится ресурс.
Кстати, путь от конечного сервера к компьютеру можно представить в виде самой обычной иерархии, показанной на рисунке №1.
Как видим, вверху стоит тот самый сервер, на котором находится нужный нам ресурс, а внизу – компьютер, то есть пользователь.
Между ними есть вспомогательные серверы.
![]()
№1. Иерархия доступа к серверу
Парсинг URL
Теперь у браузера есть следующая информация об URL:
- Protocol «HTTP» — Использовать «Hyper Text Transfer Protocol».
- Resource «/» — Показать главную (индексную) страницу.
3.1 Это URL или поисковый запрос?
Когда пользователь не вводит протокол или доменное имя, то браузер «скармливает» то, что человек напечатал, поисковой машине, установленной по умолчанию. Часто к URL добавляется специальный текст, который позволяет поисковой машине понять, что информация передана из URL-строки определённого браузера.
3.2 Список проверки HSTS
- Браузер проверяет список «предзагруженных HSTS (HTTP Strict Transport Security)». Это список сайтов, которые требуют, чтобы к ним обращались только по HTTPS.
- Если нужный сайт есть в этом списке, то браузер отправляет ему запрос через HTTPS вместо HTTP. В противном случае, начальный запрос посылается по HTTP. (При этом сайт может использовать политику HSTS, но не находиться в списке HSTS — в таком случае на первый запрос по HTTP будет отправлен ответ о том, что необходимо отправлять запросы по HTTPS. Однако это может сделать пользователя уязвимым к — чтобы этого избежать, в браузеры и включают список HSTS).
3.3 Конвертация не-ASCII Unicode символов в название хоста
- Браузер проверяет имя хоста на наличие символов, отличных от , , , , или .
- В случае доменного имени google.com никаких проблем не будет, но если бы домен содержал не-ASCII символы, то браузер бы применил кодировку Punycode для этой части URL.





