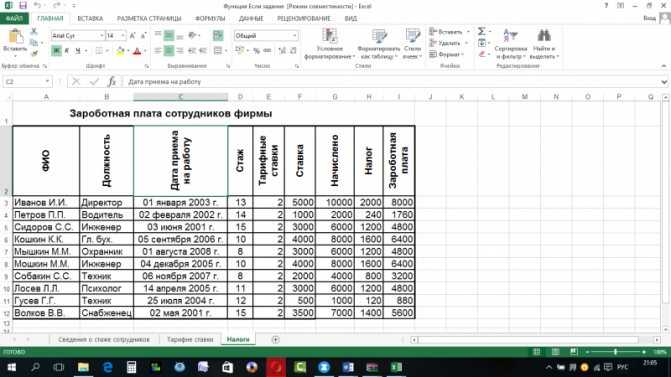
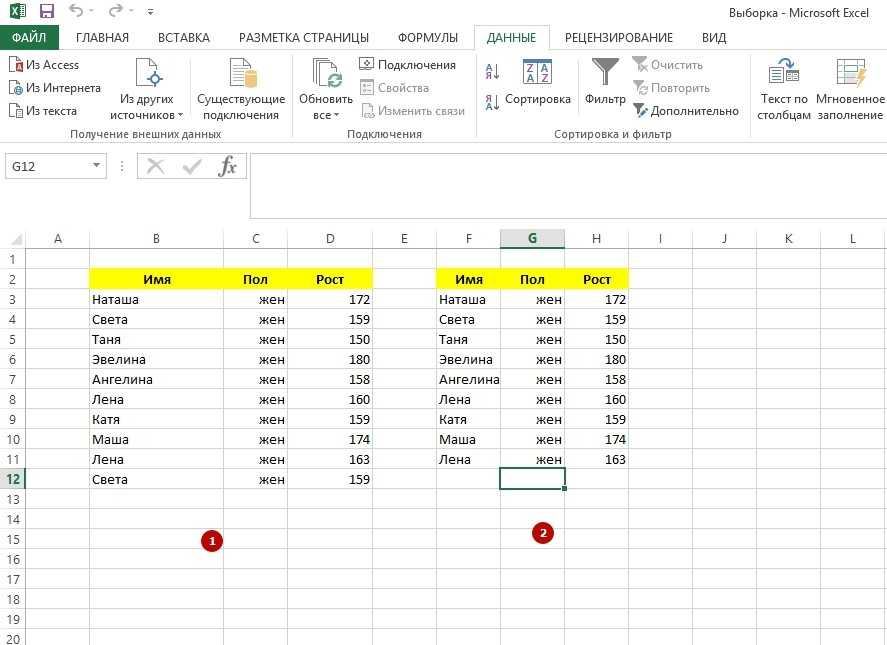
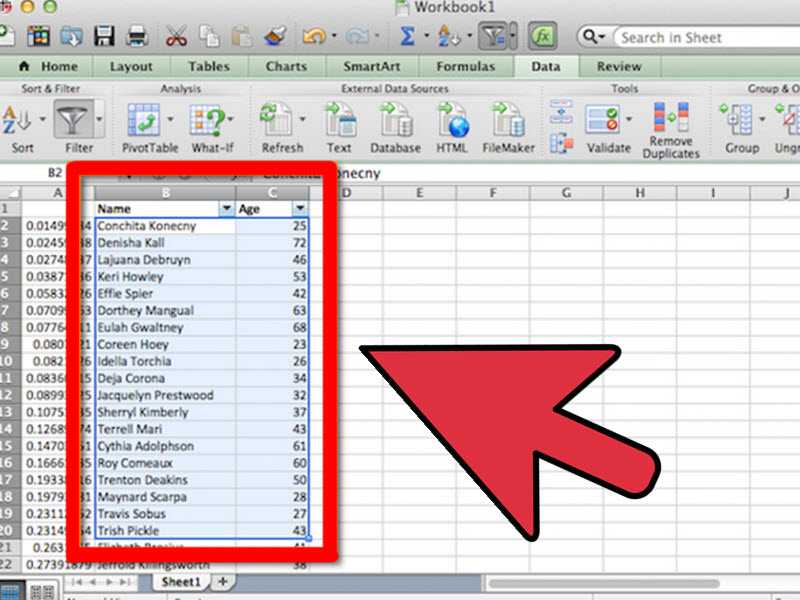
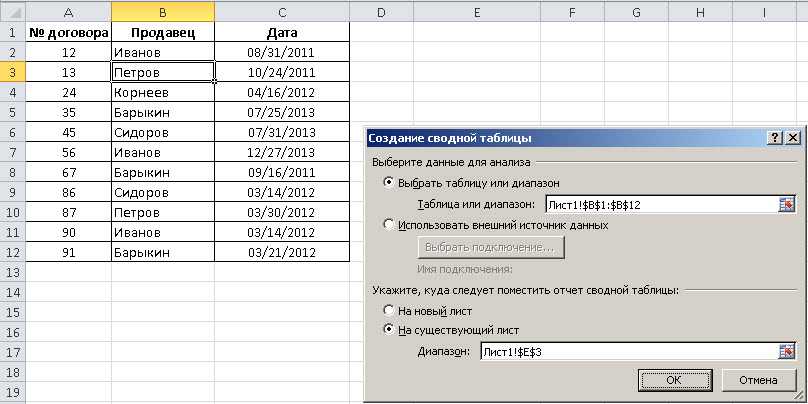
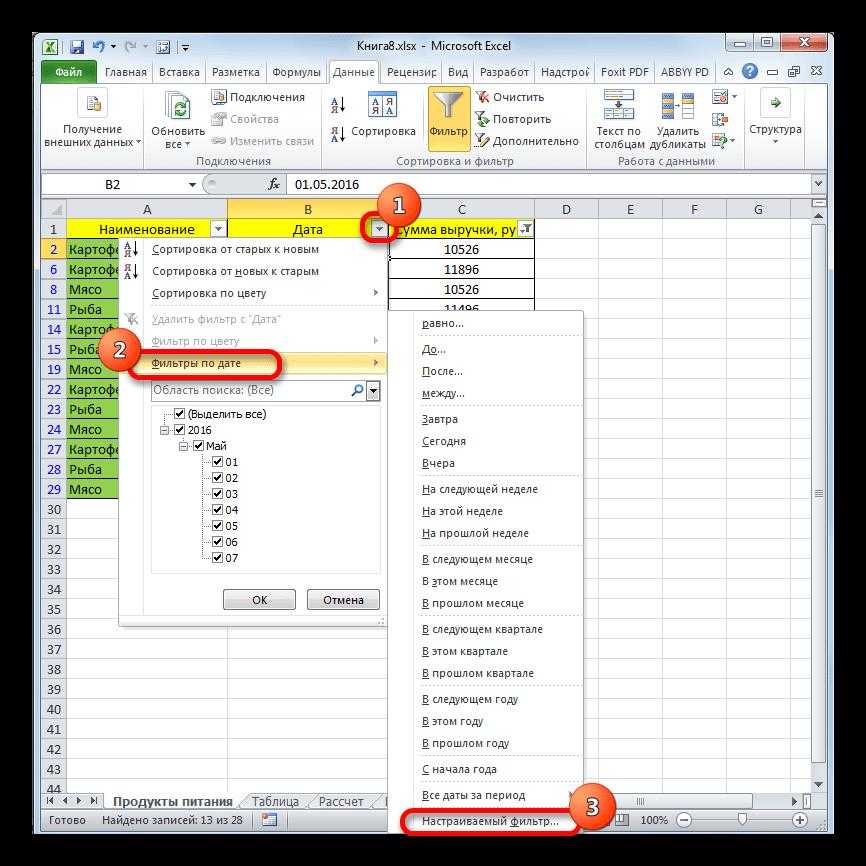
Делим текст вида ФИО по столбцам.
Если выяснение загадочных поворотов формул Excel — не ваше любимое занятие, вам может понравиться визуальный метод разделения ячеек, который демонстрируется ниже.
В столбце A нашей таблицы записаны Фамилии, имена и отчества сотрудников. Необходимо разделить их на 3 столбца.
Можно сделать это при помощи инструмента «Текст по столбцам». Об этом методе мы достаточно подробно рассказывали, когда рассматривали, как можно разделить ячейку по столбцам.
Кратко напомним:
На ленте «Данные» выбираем «Текст по столбцам» — с разделителями.
Далее в качестве разделителя выбираем пробел.
Обращаем внимание на то, как разделены наши данные в окне образца. В следующем окне определяем формат данных
По умолчанию там будет «Общий». Он нас вполне устраивает, поэтому оставляем как есть. Выбираем левую верхнюю ячейку диапазона, в который будет помещен наш разделенный текст. Если нужно оставить в неприкосновенности исходные данные, лучше выбрать B1, к примеру
В следующем окне определяем формат данных. По умолчанию там будет «Общий». Он нас вполне устраивает, поэтому оставляем как есть. Выбираем левую верхнюю ячейку диапазона, в который будет помещен наш разделенный текст. Если нужно оставить в неприкосновенности исходные данные, лучше выбрать B1, к примеру.
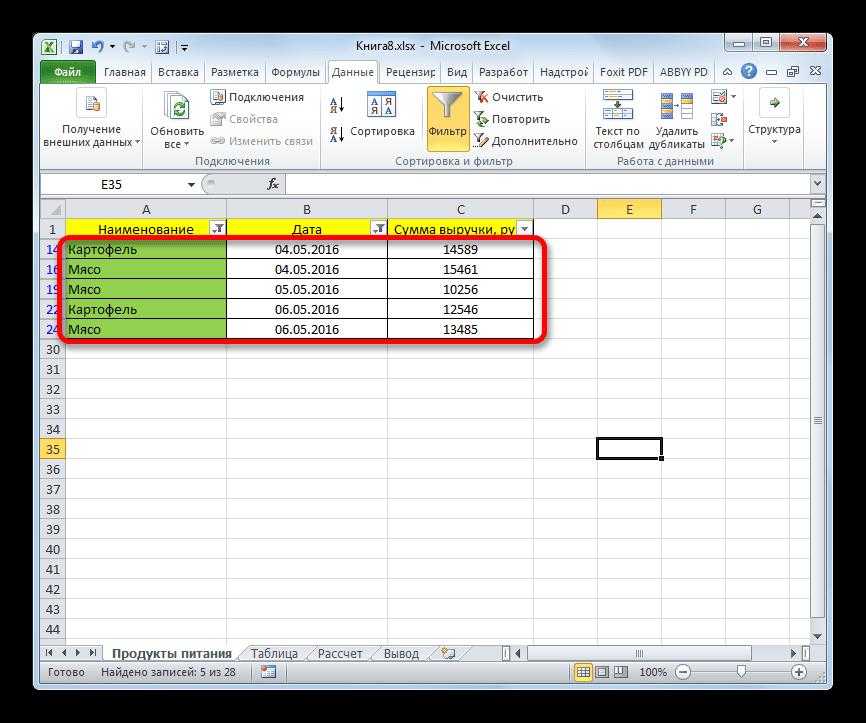
В итоге имеем следующую картину:
При желании можно дать заголовки новым столбцам B,C,D.
А теперь давайте тот же результат получим при помощи формул.
Для многих это удобнее. В том числе и по той причине, что если в таблице появятся новые данные, которые нужно разделить, то нет необходимости повторять всю процедуру с начала, а просто нужно скопировать уже имеющиеся формулы.
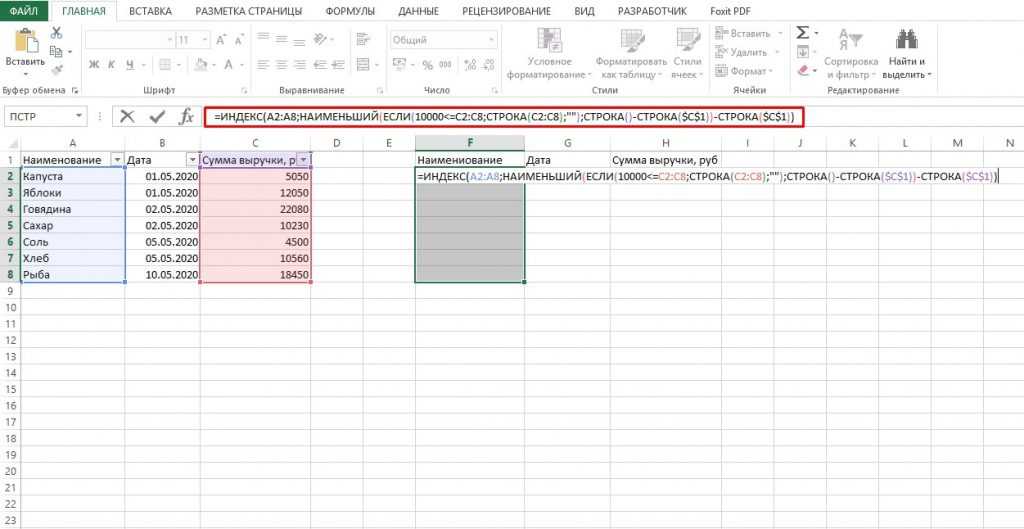
Итак, чтобы выделить из нашего ФИО фамилию, будем использовать выражение
В качестве разделителя мы используем пробел. Функция ПОИСК указывает нам, в какой позиции находится первый пробел. А затем именно это количество букв (за минусом 1, чтобы не извлекать сам пробел) мы «отрезаем» слева от нашего ФИО при помощи ЛЕВСИМВ.
Далее будет чуть сложнее.
Нужно извлечь второе слово, то есть имя. Чтобы вырезать кусочек из середины, используем функцию ПСТР.
Как вы, наверное, знаете, функция Excel ПСТР имеет следующий синтаксис:
ПСТР (текст; начальная_позиция; количество_знаков)
Текст извлекается из ячейки A2, а два других аргумента вычисляются с использованием 4 различных функций ПОИСК:
Начальная позиция — это позиция первого пробела плюс 1:
ПОИСК(» «;A2) + 1
Количество знаков для извлечения: разница между положением 2- го и 1- го пробелов, минус 1:
ПОИСК(» «;A2;ПОИСК(» «;A2)+1) — ПОИСК(» «;A2) – 1
В итоге имя у нас теперь находится в C.
Осталось отчество. Для него используем выражение:
В этой формуле функция ДЛСТР (LEN) возвращает общую длину строки, из которой вы вычитаете позицию 2- го пробела. Получаем количество символов после 2- го пробела, и функция ПРАВСИМВ их и извлекает.
Вот результат нашей работы по разделению фамилии, имени и отчества из одной по отдельным ячейкам.
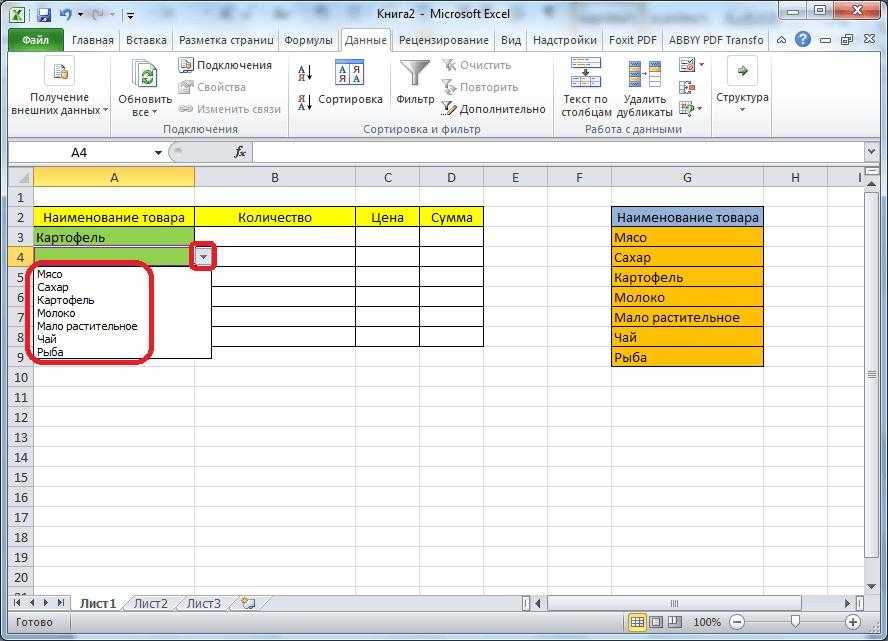
Простой выпадающий список
Несколькими щелчками мышки возможно быстро создать список в Excel. Для этого:
- Выделить столбец с конкретными наименованиями, кликнуть по нему правой кнопкой мышки. Из выпадающего меню выбрать вариант «Присвоить имя».
- Откроется окно, где в соответствующем поле меняется имя выделенного столбца. По умолчанию эксель называет его именем первой ячейки.
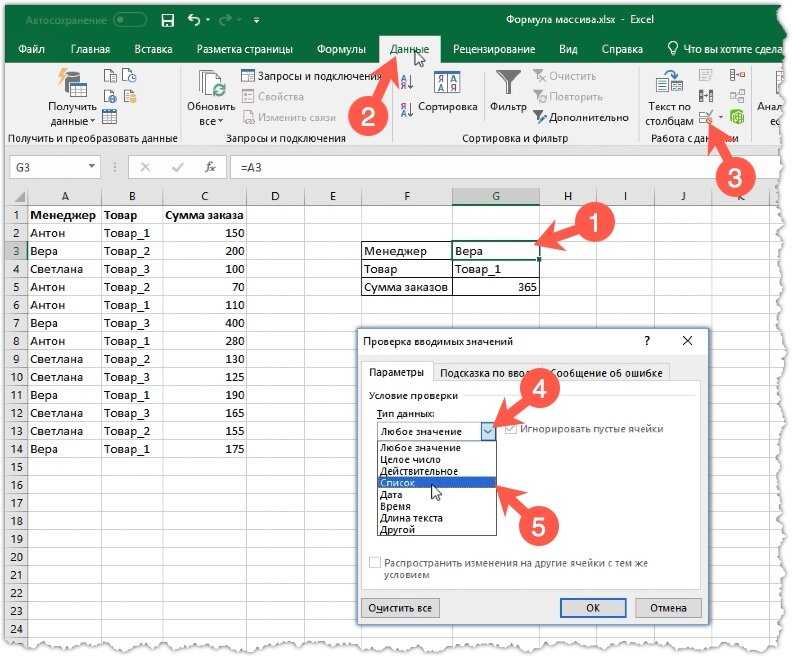
- Выделить область, куда вставить перечень. На верхней панели перейти во вкладку «Данные», далее – «Проверка данных».
- В новом окне найти параметр «Тип данных». Выбрать пункт «Список».
- Теперь указать «Источник». Кликнуть левой кнопкой мышки по полю, вписать знак «=» без кавычек и название из п.2. В качестве источника могут указываться столбцы из других листов рабочей книги. Нажать на «Ок».
- Повторить действия из п.3. В открывшемся окне перейти на вкладку «Сообщение для ввода».
- Ввести заголовок и непосредственно сообщение – некая подсказка для пользователя.
Как выбрать имя для ячеек Эксель
Есть небольшие ограничения по формату имени, которое вы можете задать. Я перечислю их, а так же дам немного рекомендаций:
- Используйте содержательные имена, чтобы по ним можно было однозначно трактовать содержание. Например, «Курс_валюты», «Индекс»инфляции» и т.п. Выбирайте короткие, но информативные названия
- Имя не должно начинаться с цифры. Не используйте знаков пунктуации, кроме подчеркивания(«_»), обратного слеш («\») и точки
- Длина имени не может превышать 255 символов, но, повторюсь, старайтесь использовать слова покороче.
- У вас не получится создать имя, совпадающее с координатами существующей ячейки. Рекомендую исключить применение названий, похожих на традиционные ссылки
- В Excel есть служебные имена диапазонов, никогда их не используйте для именования своих массивов. Например, зарезервированы: «Область_печати», «Заголовки_для_печати» и др.
В Excel легко разделять имена
Если вы сможете использовать мастер преобразования текста в столбец, вы сможете легко разделить имя и фамилию в Excel. Но если у вас есть сложные данные для работы, по крайней мере, у вас есть варианты разделения имен с помощью функций.
Для получения дополнительных уроков по Excel, подобных этим, посмотрите, как объединять и разбивать ячейки
Как объединить и разделить ячейки в Microsoft Excel
Как объединить и разделить ячейки в Microsoft ExcelСуществует причина, по которой наименьшая единица в электронной таблице Excel называется ячейкой: ее нельзя разделить дальше. Тем не менее, вот как объединить и разделить ячейки, как вы будете.
Прочитайте больше
или быстро удалите все пустые ячейки
Как быстро удалить все пустые ячейки в Excel
Как быстро удалить все пустые ячейки в ExcelУ вас есть электронная таблица Excel с пустыми строками и / или столбцами? Не тратьте время на удаление их вручную. Этот метод позволяет легко.
Прочитайте больше
в Excel.
Узнайте больше о: Microsoft Excel, Microsoft Office 2016, Microsoft Office 2019, электронная таблица.
Как извлечь имя и фамилию.
Если у вас была возможность прочитать наши недавние уроки, вы уже знаете, как вытащить имя с помощью функции ЛЕВСИМВ и получить фамилию с помощью ПРАВСИМВ. Но, как это часто бывает в Excel, одно и то же можно сделать разными способами.
Получаем имя.
Предполагая, что полное имя находится в ячейке A2, имя и фамилия разделены интервалом, вы можете извлечь имя, используя следующую формулу:
ПОИСК используется для сканирования исходного значения на предмет пробела (» «) и возврата его позиции, из которой вы вычитаете 1, чтобы избежать пробелов после имени. Затем вы используете ПСТР, чтобы вернуть подстроку, начинающуюся с первого знака и заканчивая предшествующим пробелу, таким образом извлекая первое имя.
Получаем фамилию.
Чтобы извлечь фамилию из A2, используйте эту формулу:
Опять же, вы используете ПОИСК, чтобы определить начальную позицию (пробел). Нам не нужно точно рассчитывать конечную позицию (как вы помните, если вместе взятые начальная позиция и количество символов больше, чем общая длина текста, возвращаются просто все оставшиеся). Итак, в аргументе количество символов вы просто указываете общую первоначальную длину , возвращаемую функцией ДЛСТР . Впрочем, вместо этого вы можете просто ввести число, представляющее самую длинную фамилию, которую вы ожидаете найти, например 100. Наконец, СЖПРОБЕЛЫ удаляет лишние интервалы, и вы получаете следующий результат:
Как распределить текст с разделителями на множество столбцов.
Изучив представленные выше примеры, у многих из вас, думаю, возник вопрос: «А что, если у меня не 3 слова, а больше? Если нужно разбить текст в ячейке на 5 столбцов?»
Если действовать методами, описанными выше, то формулы будут просто мега-сложными. Вероятность ошибки при их использовании очень велика. Поэтому мы применим другой метод.
Имеем список наименований одежды с различными признаками, перечисленными через дефис. Как видите, таких признаков у нас может быть от 2 до 6. Делим текст в наших ячейках на 6 столбцов так, чтобы лишние столбцы в отдельных строках просто остались пустыми.
Для первого слова (наименования одежды) используем:
Как видите, это ничем не отличается от того, что мы рассматривали ранее. Ищем позицию первого дефиса и отделяем нужное количество символов.
Для второго столбца и далее понадобится более сложное выражение:
Замысел здесь состоит в том, что при помощи функции ПОДСТАВИТЬ мы удаляем из исходного содержимого наименование, которое уже ранее извлекли (то есть, «Юбка»). Вместо него подставляем пустое значение «» и в результате имеем «Синий-M-39-42-50». В нём мы снова ищем позицию первого дефиса, как это делали ранее. И при помощи ЛЕВСИМВ вновь выделяем первое слово (то есть, «Синий»).
А далее можно просто «протянуть» формулу из C2 по строке, то есть скопировать ее в остальные ячейки. В результате в D2 получим
Обратите внимание, жирным шрифтом выделены произошедшие при копировании изменения. То есть, теперь из исходного текста мы удаляем все, что было уже ранее найдено и извлечено – содержимое B2 и C2
И вновь в получившейся фразе берём первое слово — до дефиса.
Если же брать больше нечего, то функция ЕСЛИОШИБКА обработает это событие и вставит в виде результата пустое значение «».
Скопируйте формулы по строкам и столбцам, на сколько это необходимо. Результат вы видите на скриншоте.
Таким способом можно разделить текст в ячейке на сколько угодно столбцов. Главное, чтобы использовались одинаковые разделители.
Как случайным образом заполнить значения из списка данных в Excel?
Например, у вас есть список имен, и теперь вам нужно случайным образом выбрать несколько имен и заполнить заданные ячейки, как с этим бороться? Здесь я расскажу о нескольких методах случайного заполнения значений из списка данных в Excel.
Произвольно заполнять значения из списка данных функциями
Чтобы случайным образом заполнить значения из заданного списка данных в Excel, мы можем применить функцию RANDBETWEEN и функцию VLOOKUP, чтобы сделать это следующим образом:
Шаг 1: Щелкните правой кнопкой мыши столбец данного списка и выберите Вставить из контекстного меню.
![]()
Шаг 2: Во вставленном столбце введите NO. в качестве заголовка столбца, а затем введите порядковые номера в следующие ячейки, как показано на скриншоте выше:
Шаг 3: Случайным образом заполнять указанные ячейки из данного списка:
![]()
(1) В пустую ячейку введите формулу = СЛУЧМЕЖДУ (1,15), и перетащите маркер заполнения в нужный диапазон.
(2) В ячейку, в которую вы будете вводить имя случайным образом из данного списка, введите формулу = ВПР (C2; $ A $ 1: $ B $ 16,2; FALSE), и перетащите маркер заполнения в нужный диапазон.
Ноты:
(1) В формуле = СЛУЧМЕЖДУ (1,15), 1 — наименьший порядковый номер, а 15 — наибольший.
(2) В формуле = ВПР (C2; $ A $ 1: $ B $ 16,2; FALSE), C2 — это случайный порядковый номер, который вы получили только что, $ A $ 1: $ B $ 16 — это диапазон заданного списка и вставленных порядковых номеров, 2 означает второй столбец в диапазоне $ A $ 1: $ B $ 16.
| Формула слишком сложна для запоминания? Сохраните формулу как запись Auto Text для повторного использования одним щелчком мыши в будущем! Бесплатная пробная версия |
Функции RANDBETWEEN и VLOOKUP могут легко помочь вам в случайном заполнении имен из данного списка в Excel. Однако этот метод оставляет две проблемы:
- Случайные имена меняются после обновления текущего рабочего листа, например, ввод новой формулы в рабочий лист или просто двойной щелчок в ячейке, а затем выход и т. Д.
- Повторяющиеся имена иногда заполняются в указанных ячейках.
Случайно заполняйте значения из списка данных с помощью Kutools for Excel
Чтобы случайным образом заполнить имена из данного списка без дубликатов и сохранить все заполненные имена статичными, вы можете попробовать Kutools for Excel’s Вставить случайные данные утилита, чтобы сделать это с легкостью.
Kutools for Excel — Включает более 300 удобных инструментов для Excel. Полнофункциональная бесплатная 30-дневная пробная версия, кредитная карта не требуется! Бесплатная пробная версия сейчас!
Шаг 1: Нажмите Kutools > Вставить > Вставить случайные данные.
![]()
Шаг 2: В открывшемся диалоговом окне Вставка случайных данных перейдите к Пользовательский список , нажмите Добавить кнопка; затем в открывшемся диалоговом окне Create Sequence щелкните значок
кнопка; в новом диалоговом окне укажите диапазон заданного списка имен; следующий щелчок OK > Ok.![]()
Шаг 3: Теперь указанный список имен добавлен как настраиваемый список в диалоговом окне «Вставить случайные данные». Выберите диапазон, в который вы будете случайным образом заполнять имена из данного списка, нажмите кнопку Ok или Применить кнопку.
![]()
Внимание: Для случайного заполнения имен из данного списка без дубликатов, пожалуйста, проверьте Уникальные ценности в диалоговом окне «Вставить случайные данные». См
Снимок экрана выше.
Демонстрация: случайное заполнение значений из списка данных в Excel
Kutools for Excel включает более 300 удобных инструментов для Excel, которые можно бесплатно попробовать без ограничений в течение 30 дней. Скачать и бесплатную пробную версию сейчас!
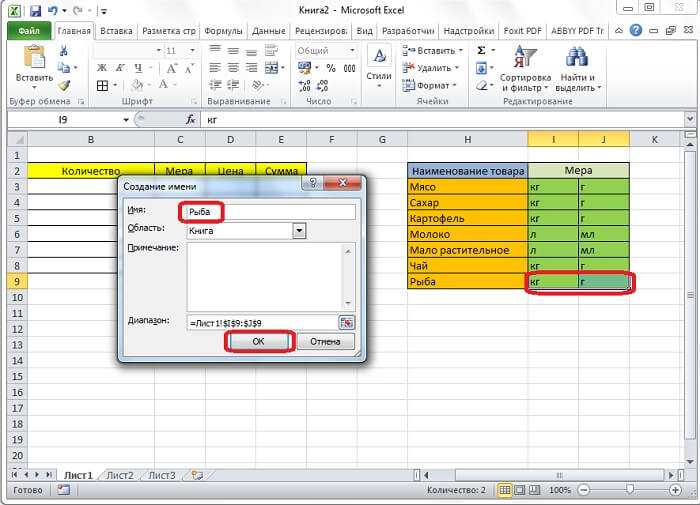
Создание имён из выделенных таблиц
Предположим, у вас есть таблица исходных данных для расчётов. В столбце «А» записаны названия параметров, а в столбце «В» — их значения. Нужно назвать эти значения именами, указанными в столбце А. Выделите всю таблицу и выполните: Формулы – Определение имени – Создать из выделенного. Откроется диалоговое окно, где нужно выбрать расположение названий. В нашем примере наименования находятся слева от данных, поэтому выбираем В столбце слева. Программа сама создаёт названия и присваивает имена из столбца слева.
Если какое-то значение не подписано в этом столбце, или подпись некорректна, её не получается исправить автоматически – Эксель не создаст имя. Если в именах присутствуют пробелы, они будут заменены на знаки нижнего подчёркивания.
![]() Создание имён из выделенного диапазона
Создание имён из выделенного диапазона
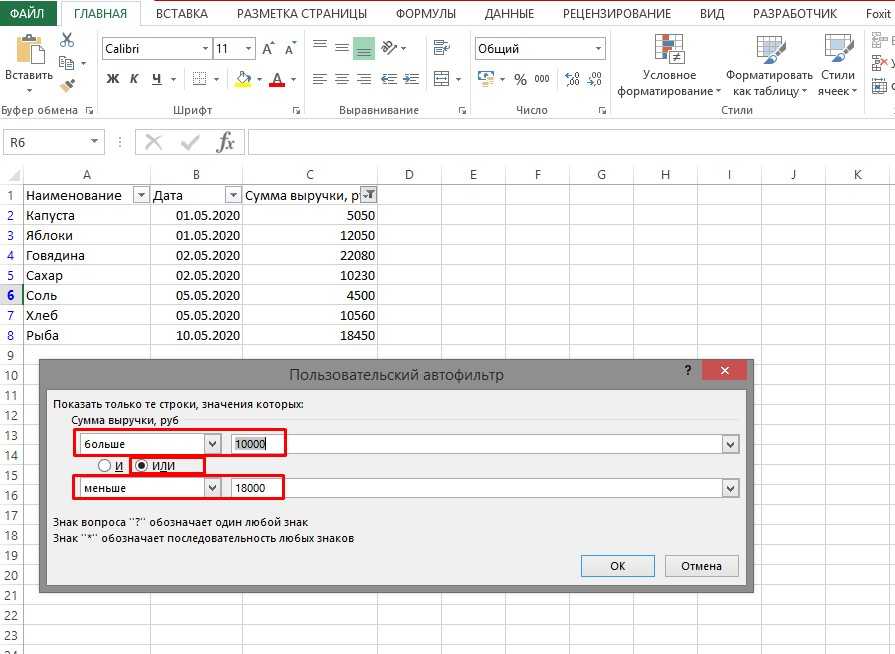
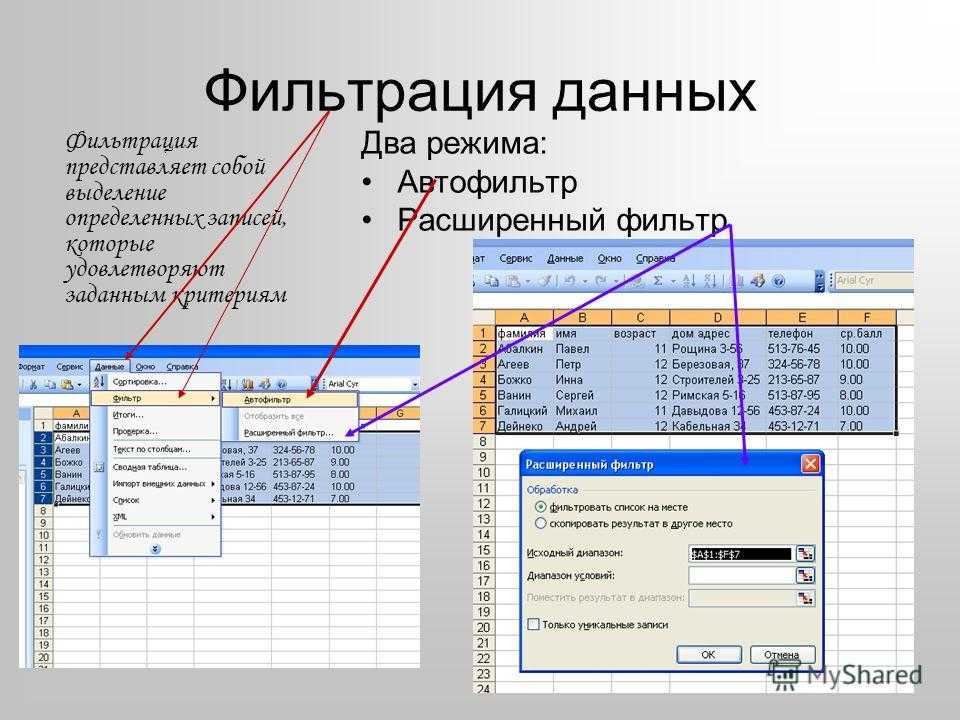
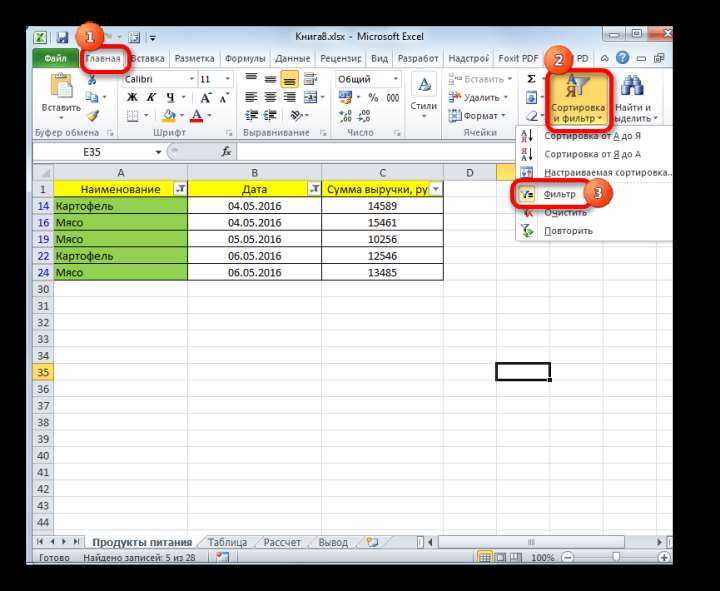
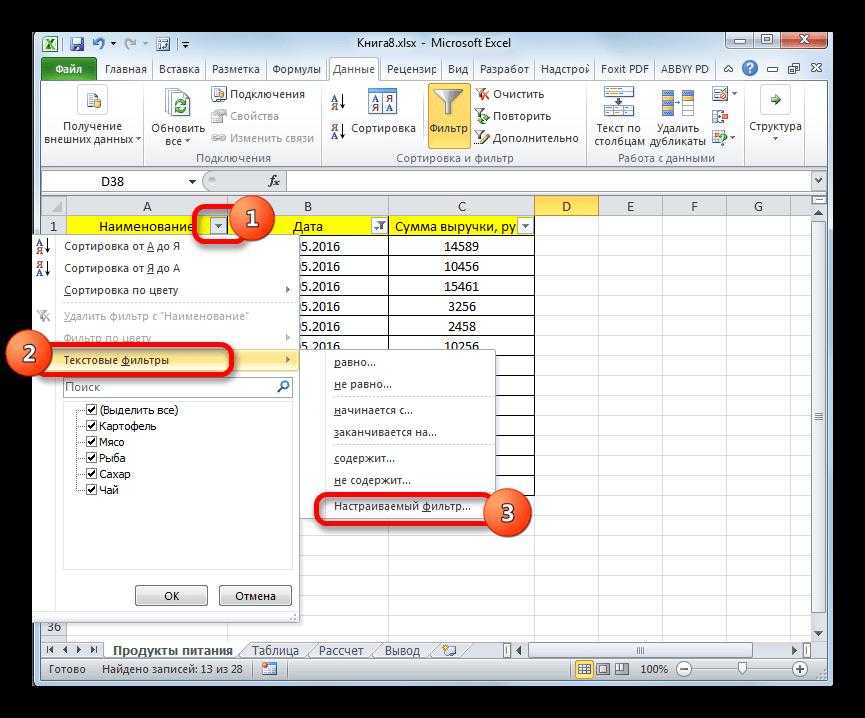
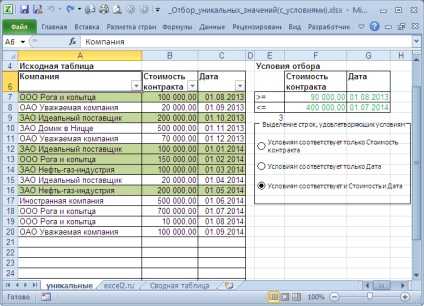
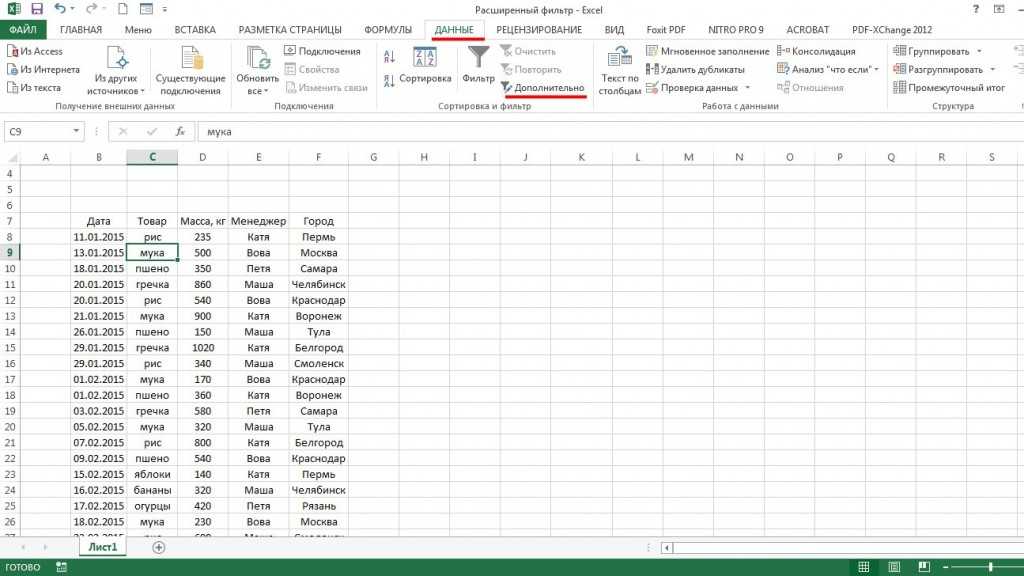
Использование расширенного фильтра.
Если вы не хотите тратить время на выяснение загадочных поворотов формул, вы можете быстро получить список уникальных значений с помощью расширенного фильтра. Подробные инструкции приведены ниже.
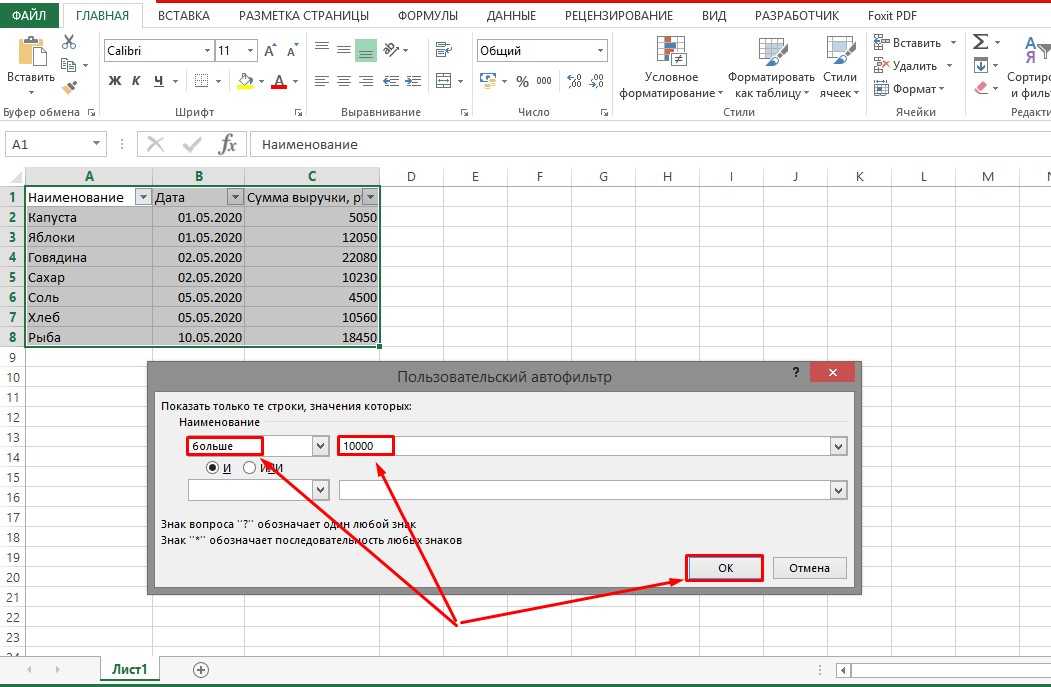
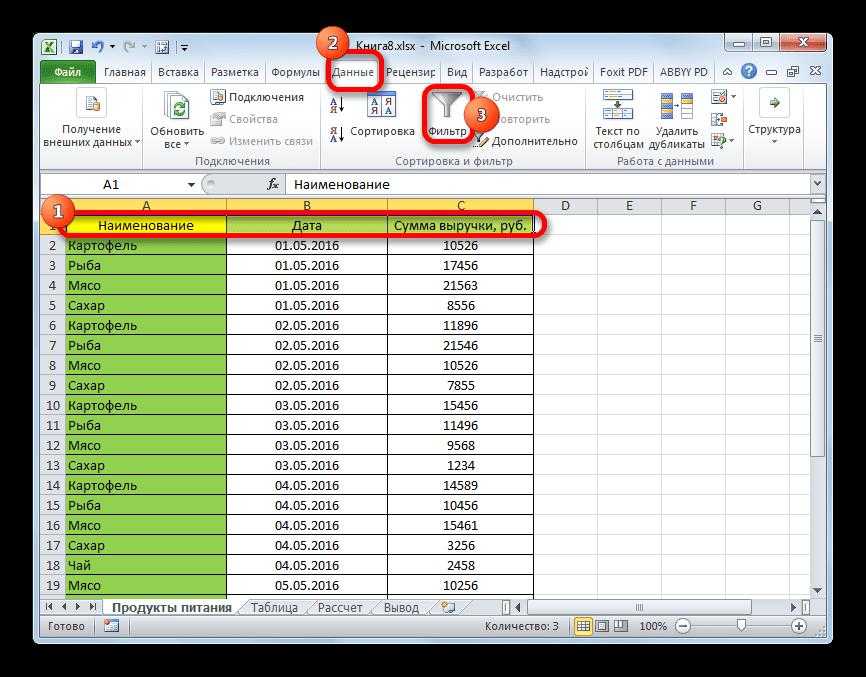
- Выберите столбец данных, из которого вы хотите извлечь отдельные значения.
- Перейдите на вкладку «Данные» > группа «Сортировка и фильтр» и нажмите кнопку «Дополнительно .
- В диалоговом окне Расширенный фильтр выберите следующие параметры:
- Установите флажок Копировать в другое место .
- В поле Исходный диапазон убедитесь, что он указан правильно.
- В параметре Поместить результат в… укажите самую верхнюю ячейку целевого диапазона. Помните, что вы можете копировать отфильтрованные данные только на текущий лист.
- Выберите пункт «Только уникальные записи».
- Наконец, нажмите кнопку ОК и проверьте результат.
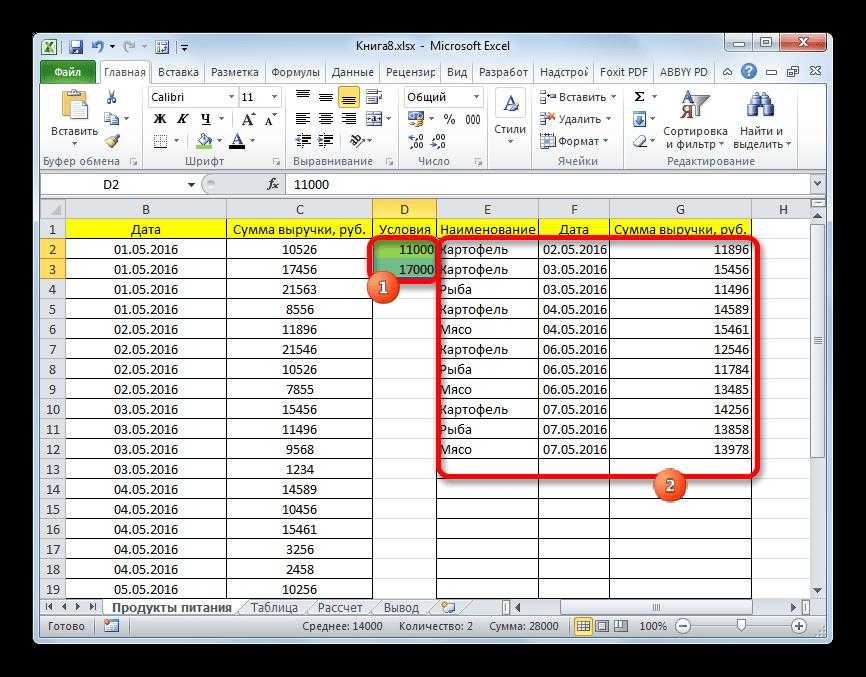
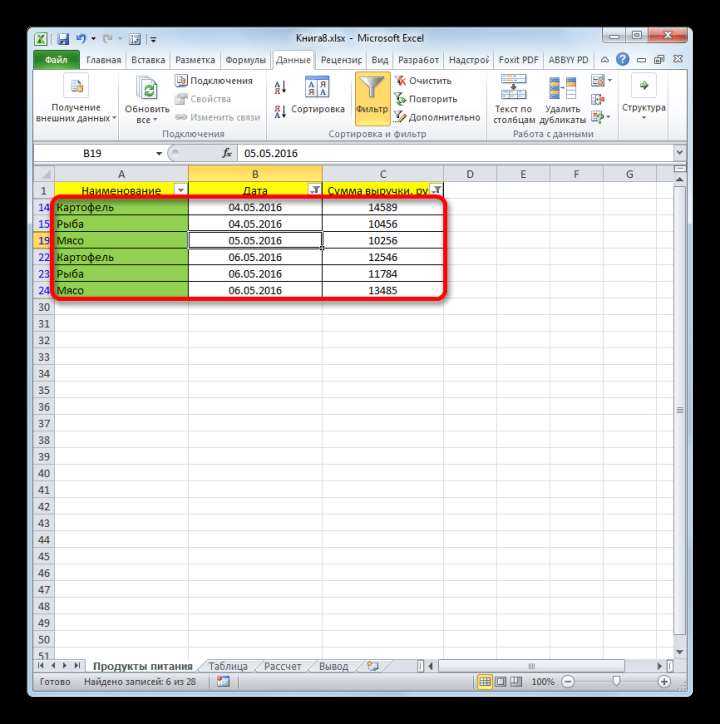
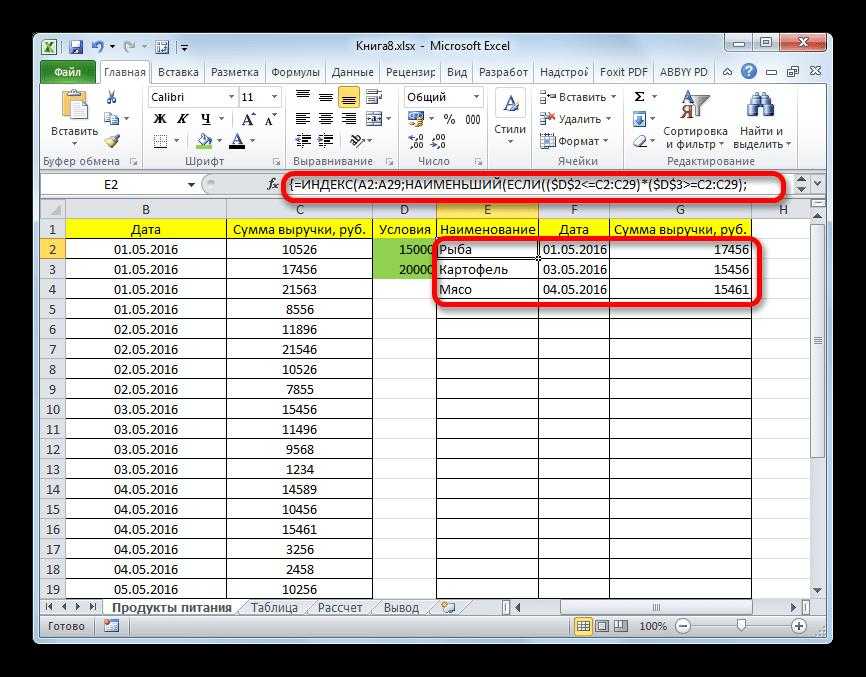
Как видите, мы проверили колонку B, и затем список уникальных наименований товара, найденных в ней, поместили в столбец K.
Обратите внимание, что хотя опция расширенного фильтра называется «Только уникальные записи», она извлекает различные значения, то есть уникальные и первые вхождения повторяющихся. Теперь немного усложним задачу
Теперь немного усложним задачу.
Если требуется искать записи не по одному, а по нескольким столбцам, то можно их предварительно «склеить» при помощи функции СЦЕПИТЬ.
Записываем это в столбец F и копируем вниз. Получаем вспомогательную колонку.
В качестве исходного диапазона мы по-прежнему выбираем данные, из которых извлекаем уникальные значения. Теперь это два столбца – A и B.
Но искать уникальные мы по-прежнему можем только в одном столбце. Вот для этого нам и пригодится вспомогательная колонка F с объединенными данными. Ее то мы и указываем в поле «Диапазон условий».
Все остальное – так же, как и в предыдущем примере.
В результате мы получили все имеющиеся в таблице комбинации «Заказчик — Товар» на основе данных во вспомогательном столбце F.
Думаю, вы понимаете, что аналогичные действия можно произвести и с тремя столбцами (например Фамилия – Имя – Отчество). Главное условие – исходный диапазон должен быть непрерывным, то есть все столбцы должны находиться рядом.
Как видите формулы здесь не нужны. Однако, если исходные данные изменятся, то все манипуляции придется повторять заново.
Как нам это может пригодиться?
Часто случается так, что в какой-то из колонок вашей таблицы нужно вводить одинаковые повторяющиеся значения. К примеру, фамилии сотрудников, названия товаров. Что может случиться? Конечно, в первую очередь будут ошибки при вводе. Человеческий фактор ведь никто не отменял. Чем нам сие грозит? К примеру, когда мы решим подсчитать, сколько заказов выполнил каждый из менеджеров, то окажется, что фамилий больше, чем сотрудников. Далее придётся искать ошибки, исправлять их и вновь повторять расчет.
Ну и конечно же, все время руками вводить одни и те же слова – просто бессмысленная работа и потеря времени. Вот здесь-то выпадающие списки нам и пригодятся. При нажатии выпадает перечень заранее определённых значений, из которых необходимо указать только одно.
Важно то, что вы теперь будете не вводить, а выбирать их с помощью мыши или клавиатуры. Это значительно ускоряет работу, а также гарантирует защиту от случайных ошибок
Проверка того, что мы вписали в таблицу, теперь уже не нужна.
Заполнение диапазона
Чтобы заполнить диапазон, следуйте инструкции ниже:
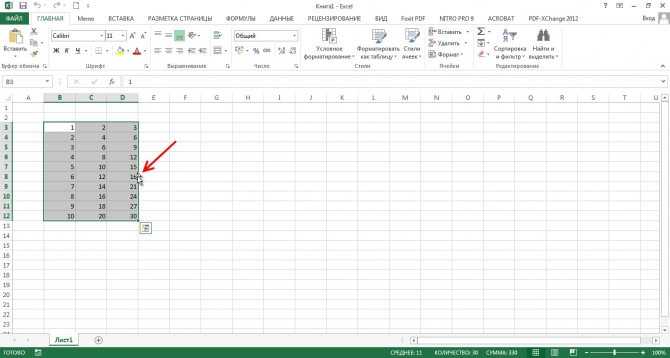
- Введите значение 2 в ячейку B2.
-
Выделите ячейку В2, зажмите её нижний правый угол и протяните вниз до ячейки В8.Результат:
Эта техника протаскивания очень важна, вы будете часто использовать её в Excel. Вот еще один пример:
- Введите значение 2 в ячейку В2 и значение 4 в ячейку B3.
- Выделите ячейки B2 и B3, зажмите нижний правый угол этого диапазона и протяните его вниз.Excel автоматически заполняет диапазон, основываясь на шаблоне из первых двух значений. Классно, не правда ли? Вот еще один пример:
- Введите дату 13/6/2013 в ячейку В2 и дату 16/6/2013 в ячейку B3 (на рисунке приведены американские аналоги дат).
- Выделите ячейки B2 и B3, зажмите нижний правый угол этого диапазона и протяните его вниз.
Создание списка посредством контекстного меню
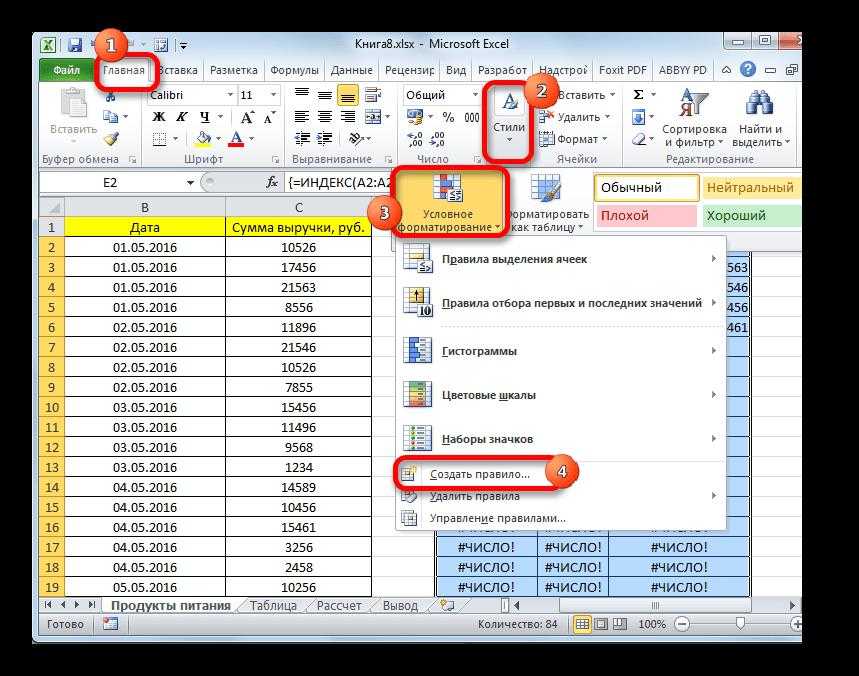
Считается самым простым и понятным методом, когда нужно сделать выпадающий список в экселе в другом месте текущего документа: на новом листе, рядом с таблицами. Это позволяет структурировать информацию.
Инструкция проста и состоит из нескольких шагов:
• в дополнительной таблице фиксируем наименования (каждое с новой строчки в отдельной ячейке), чтобы получился один столбец;
![]()
• далее нужно выделить ячейки, кликнуть правой кнопкой мыши в любом выделенном месте и выбрать из выпавшего списка функцию «Присвоить имя»;
![]()
• должно появиться окно с созданием имени. Пользователь может назвать список по собственному желанию, но первый символ обязательно должна быть буква. Также не допускается использование определенных символов. При необходимости разрешается создать примечание к списку. Нажать ОК;
![]()
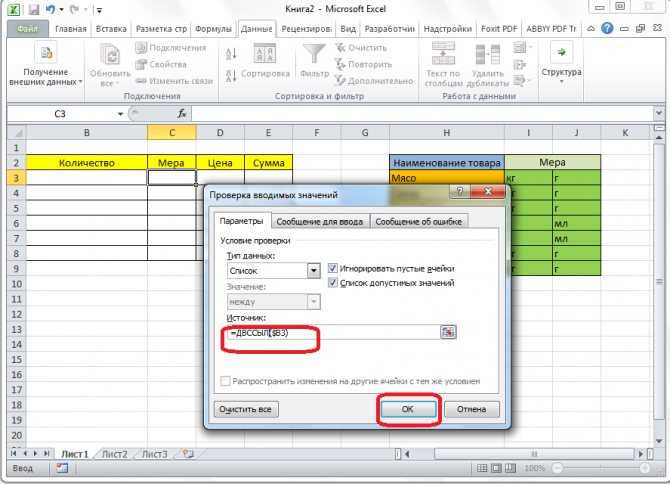
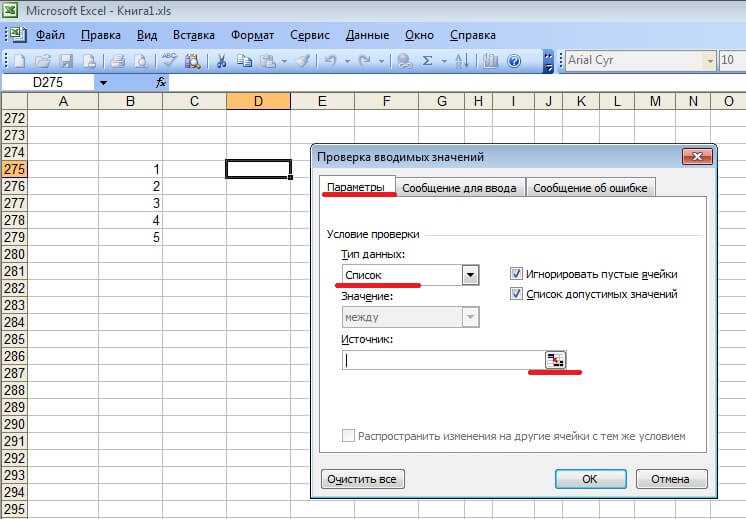
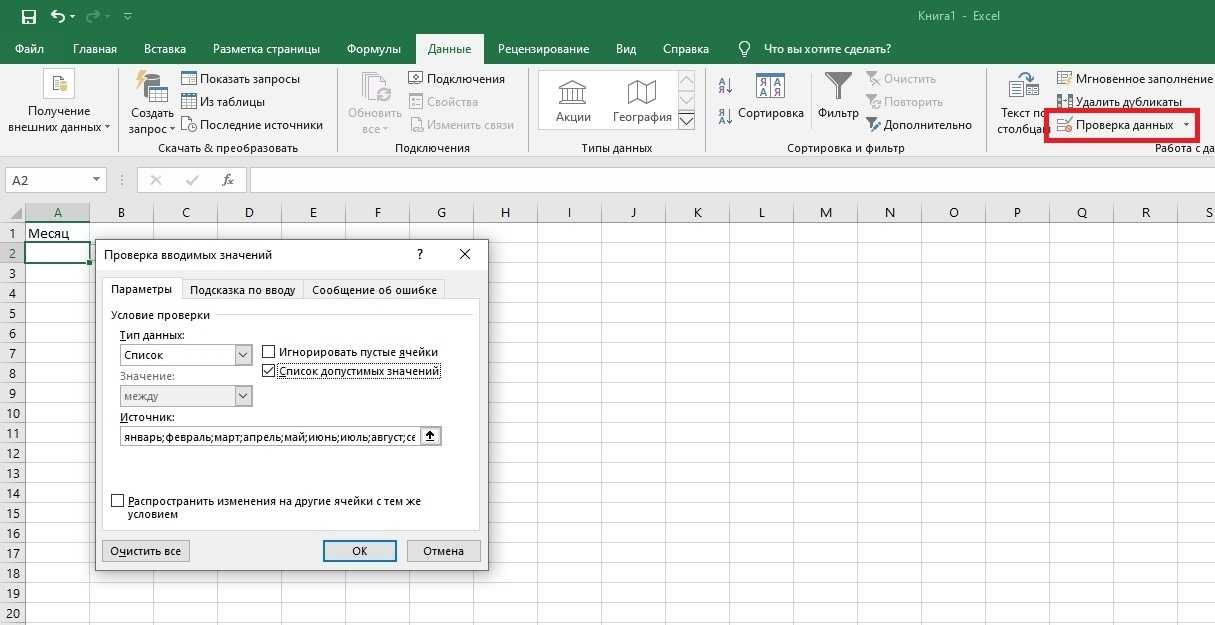
• переключиться на вкладку «Данные» в главном окне экселя. Отметить группу с ячейками, для которой потребуется создать список и кликнуть на кнопку «Проверка данных» и выбрать подпункт «работа с данными»;
![]()
• должно появиться окно «проверка вводимых значений». В параметрах найти подпункт список. В «источнике» поставить = «название списка». Нажать ОК;
![]()
• если все действия выполнены правильно, должен появиться значок со стрелкой вниз. Нажимая на значок, автоматически откроется созданный список. Кликая по любому наименованию, значение будет вставлено в ячейку.
![]()
Основным преимуществом метода является минимальная вероятность опечаток.
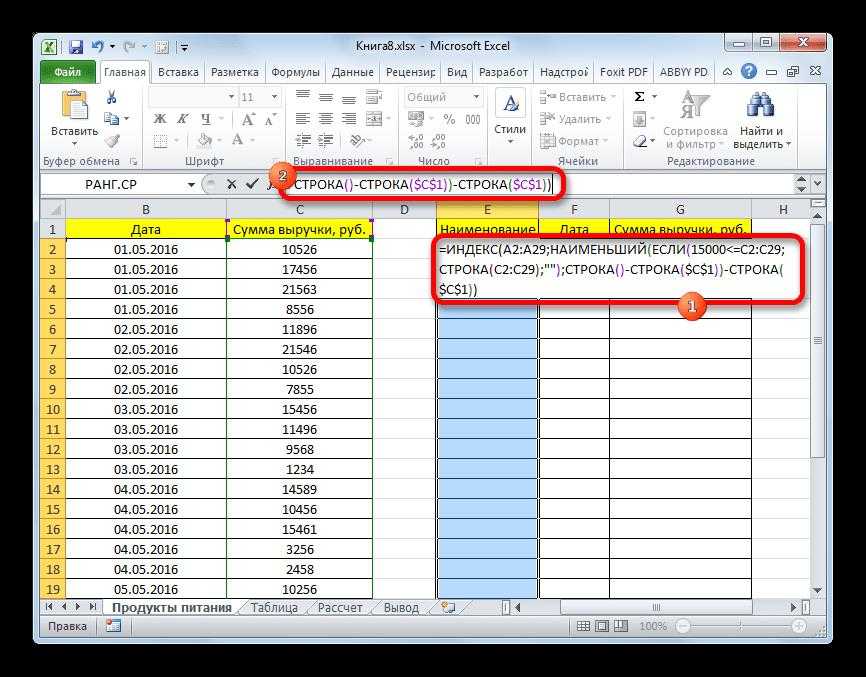
Как извлечь значения, игнорируя пустые ячейки
Если исходный список содержит пустые ячейки, формула, которую мы только что обсудили, вернет ноль для каждой пустой строки, что может быть проблемой. Это вы и наблюдаете на скриншоте чуть выше. Чтобы исправить это, сделаем несколько небольших корректировок.
Формула массива для извлечения различных значений, исключая пустые ячейки:
Аналогичным образом вы можете получить список различных значений, исключая пустые ячейки и ячейки с числами:
Напоминаем, что в приведенных выше формулах A2: A13 – это исходный список, а B1 – ячейка прямо над первой позицией формируемого списка.
На этом скриншоте показан результат отбора:
![]()
Быть может, кому-то будет полезна еще одна формула –
Она работает с числами и текстом, игнорирует пустые ячейки.
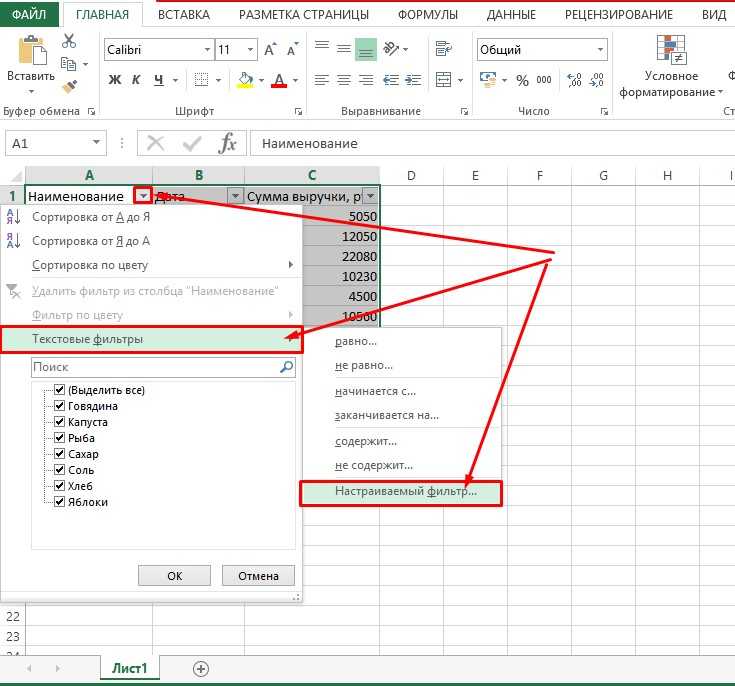
Поиск нестрогого соответствия символов
Иногда пользователь не знает точного сочетания искомых символов что существенно затрудняет поиск. Данные также могут содержать различные опечатки, лишние пробелы, сокращения и пр., что еще больше вносит путаницы и делает поиск практически невозможным. А может случиться и обратная ситуация: заданной комбинации соответствует слишком много ячеек и цель поиска снова не достигается (кому нужны 100500+ найденных ячеек?).
Для решения этих проблем очень хорошо подходят джокеры (подстановочные символы), которые сообщают Excel о сомнительных местах. Под джокерами могут скрываться различные символы, и Excel видит лишь их относительное расположение в поисковой фразе. Таких джокеров два: звездочка «*» (любое количество неизвестных символов) и вопросительный знак «?» (один «?» – один неизвестный символ).
Так, если в большой базе клиентов нужно найти человека по фамилии Иванов, то поиск может выдать несколько десятков значений. Это явно не то, что вам нужно. К поиску можно добавить имя, но оно может быть внесено самым разным способом: И.Иванов, И. Иванов, Иван Иванов, И.И. Иванов и т.д. Используя джокеры, можно задать известную последовательно символов независимо от того, что находится между. В нашем примере достаточно ввести и*иванов и Excel отыщет все выше перечисленные варианты записи имени данного человека, проигнорировав всех П. Ивановых, А. Ивановых и проч. Секрет в том, что символ «*» сообщает Экселю, что под ним могут скрываться любые символы в любом количестве, но искать нужно то, что соответствует символам «и» + что-еще + «иванов». Этот прием значительно повышает эффективность поиска, т.к. позволяет оперировать не точными критериями.
Если с пониманием искомой информации совсем туго, то можно использовать сразу несколько звездочек. Так, в списке из 1000 позиций по поисковой фразе мол*с*м*уход я быстро нахожу позицию «Мол-ко д/сн мак. ГАРНЬЕР Осн.уход д/сух/чув.к. 200мл» (это сокращенное название от «Молочко для снятия макияжа Гараньер Основной уход….»). При этом очевидно, что по фразе «молочко» или «снятие макияжа» поиск ничего бы не дал. Часто достаточно ввести первые буквы искомых слов (которые наверняка присутствуют), разделяя их звездочками, чтобы Excel показал чудеса поиска. Главное, чтобы последовательность символов была правильной.
Есть еще один джокер – знак «?». Под ним может скрываться только один неизвестный символ. К примеру, указав для поиска критерий 1?6, Excel найдет все ячейки содержащие последовательность 106, 116, 126, 136 и т.д. А если указать 1??6, то будут найдены ячейки, содержащие 1006, 1016, 1106, 1236, 1486 и т.д. Таким образом, джокер «?» накладывает более жесткие ограничения на поиск, который учитывает количество пропущенных знаков (равный количеству проставленных вопросиков «?»).
В случае неудачи можно попробовать изменить поисковую фразу, поменяв местами известные символы, сократив их, добавить новые подстановочные знаки и др. Однако это еще не все нюансы поиска. Бывают ситуации, когда в упор наблюдаешь искомую ячейку, но поиск почему-то ее не находит.
Извлечение уникальных значений с помощью Duplicate Remover.
В заключительной части этого руководства я покажу вам интересное решение для поиска и извлечения различных и уникальных значений в таблицах Excel. Это решение сочетает в себе универсальность формул Excel и простоту расширенного фильтра. Кроме того, здесь есть несколько уникальных функций:
- Найти и извлечь уникальные или различные значения на основе записей в одном или нескольких столбцах.
- Найти, выделить и скопировать уникальные значения в любое другое место в той же или другой книге Excel.
А теперь давайте посмотрим, как работает инструмент Duplicate Remover.
Предположим, у вас есть большая таблица, созданная путем объединения данных из нескольких других таблиц. Очевидно, что она содержит много повторяющихся строк, и ваша задача состоит в том, чтобы извлечь уникальные строки, которые появляются в таблице только один раз, или различные строки, включая уникальные и первые повторяющиеся вхождения. В любом случае, с надстройкой Duplicate Remover работа выполняется за несколько шагов.
- Выберите любую ячейку в исходной таблице и нажмите кнопку DuplicateRemover на вкладке AblebitsData в группе Dedupe.
Мастер Duplicate Remover запустится и выберет всю таблицу. Итак, просто нажмите « Далее», чтобы перейти к следующему шагу.
- Выберите тип значения, который вы хотите найти, и нажмите Далее :
- Уникальные
- Уникальные + 1е вхождения (различные)
В этом примере мы хотим извлечь различные строки, которые появляются в исходной таблице хотя бы один раз, поэтому мы выбираем опцию Unique + 1st occurences:
- Выберите один или несколько столбцов для проверки уникальных значений.
В этом примере мы хотим убрать все повторяющиеся значения на основе значений в 2 столбцах ( заказчик и товар), поэтому мы выбираем только нужные нам столбцы.
В нашем случае таблица имеет заголовок, поэтому отмечаем птичкой пункт My table has headers.
Думаю, нам не нужны пустые строки, которые могут случайно встретиться при объединении данных из разных таблиц. Поэтому отмечаем такжеSkip empty cells.
Если вдруг в наших записях случайно появились лишние пробелы, то, думаю, стоит их игнорировать. Поэтому отмечаем также Ignore extra spaces.
Также наш поиск буден нечувствителен к регистру, то есть не будем при сравнении данных различать прописные и строчные буквы. Поэтому не трогаем опцию Case-sensitive match.
- Выберите действие, которое нужно выполнить с найденными значениями. Вам доступны следующие варианты:
- Выделить цветом.
- Выбрать и выделить.
- Отметить в столбце статуса.
- Копировать в другое место.
Чтобы не менять исходные данные, выберите «Копировать в другое место» (Copy to another location), а затем укажите, где именно вы хотите видеть новую таблицу – на этом же листе (выберите параметр «Custom Location» и укажите верхнюю ячейку целевого диапазона), на новом листе (New worksheet) или в новой книге (New workbook).
В этом примере давайте выберем новый лист:
- Нажмите кнопку « Готово» , и все готово!
В итоге у нас осталось всего 20 записей.
Понравился этот быстрый и простой способ получить список уникальных значений или записей в Excel? Если да, то я рекомендую вам загрузить полнофункциональную ознакомительную версию Ultimate Suite и попробовать в работе Duplicate Remover.
В Ultimate Suite for Excel также включено много других полезных инструментов, которые помогут вам сэкономить много времени. Мы о них также будем подробно рассказывать в других материалах на сайте.
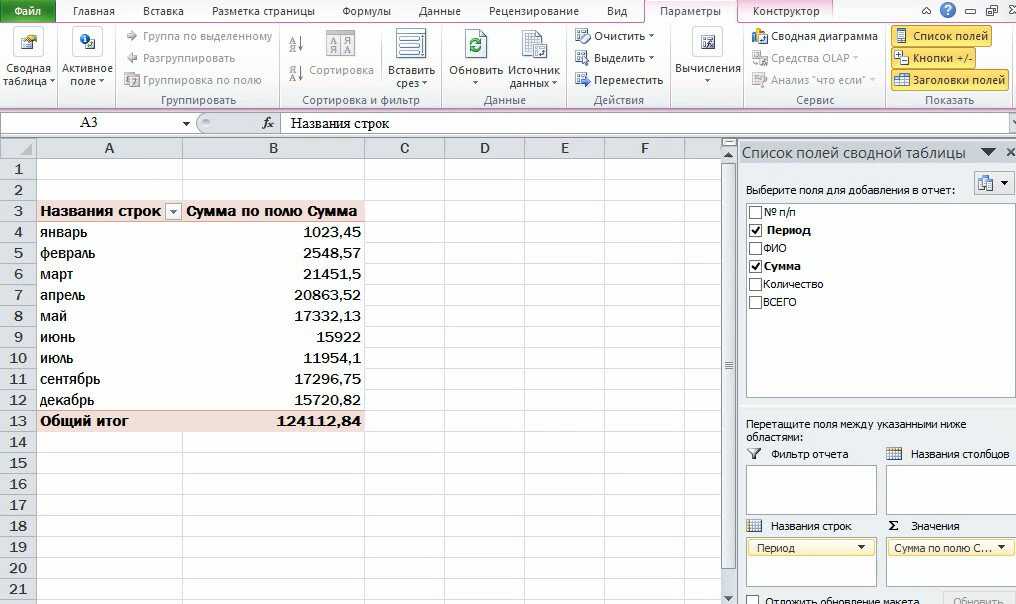
Автозаполнение в Excel из списка данных
Ясно, что кроме дней недели и месяцев могут понадобиться другие списки. Допустим, часто приходится вводить перечень городов, где находятся сервисные центры компании: Минск, Гомель, Брест, Гродно, Витебск, Могилев, Москва, Санкт-Петербург, Воронеж, Ростов-на-Дону, Смоленск, Белгород. Вначале нужно создать и сохранить (в нужном порядке) полный список названий. Заходим в Файл – Параметры – Дополнительно – Общие – Изменить списки.
В следующем открывшемся окне видны те списки, которые существуют по умолчанию.
Как видно, их не много. Но легко добавить свой собственный. Можно воспользоваться окном справа, где либо через запятую, либо столбцом перечислить нужную последовательность. Однако быстрее будет импортировать, особенно, если данных много. Для этого предварительно где-нибудь на листе Excel создаем перечень названий, затем делаем на него ссылку и нажимаем Импорт.
Помимо текстовых списков чаще приходится создавать последовательности чисел и дат. Один из вариантов был рассмотрен в начале статьи, но это примитивно. Есть более интересные приемы. Вначале нужно выделить одно или несколько первых значений серии, а также диапазон (вправо или вниз), куда будет продлена последовательность значений. Далее вызываем диалоговое окно прогрессии: Главная – Заполнить – Прогрессия.
Рассмотрим настройки.
В левой части окна с помощью переключателя задается направление построения последовательности: вниз (по строкам) или вправо (по столбцам).
Посередине выбирается нужный тип:
- арифметическая прогрессия – каждое последующее значение изменяется на число, указанное в поле Шаг
- геометрическая прогрессия – каждое последующее значение умножается на число, указанное в поле Шаг
- даты – создает последовательность дат. При выборе этого типа активируются переключатели правее, где можно выбрать тип единицы измерения. Есть 4 варианта:
-
-
- день – перечень календарных дат (с указанным ниже шагом)
- рабочий день – последовательность рабочих дней (пропускаются выходные)
- месяц – меняются только месяцы (число фиксируется, как в первой ячейке)
- год – меняются только годы
-
автозаполнение – эта команда равносильная протягиванию с помощью левой кнопки мыши. То есть эксель сам определяет: то ли ему продолжить последовательность чисел, то ли продлить список. Если предварительно заполнить две ячейки значениями 2 и 4, то в других выделенных ячейках появится 6, 8 и т.д. Если предварительно заполнить больше ячеек, то Excel рассчитает приближение методом линейной регрессии, т.е. прогноз по прямой линии тренда (интереснейшая функция – подробнее см. ниже).
Нижняя часть окна Прогрессия служит для того, чтобы создать последовательность любой длины на основании конечного значения и шага. Например, нужно заполнить столбец последовательностью четных чисел от 2 до 1000. Мышкой протягивать не удобно. Поэтому предварительно нужно выделить только ячейку с одним первым значением. Далее в окне Прогрессия указываем Расположение, Шаг и Предельное значение.
Результатом будет заполненный столбец от 2 до 1000. Аналогичным образом можно сделать последовательность рабочих дней на год вперед (предельным значением нужно указать последнюю дату, например 31.12.2016). Возможность заполнять столбец (или строку) с указанием последнего значения очень полезная штука, т.к. избавляет от кучи лишних действий во время протягивания. На этом настройки автозаполнения заканчиваются. Идем далее.
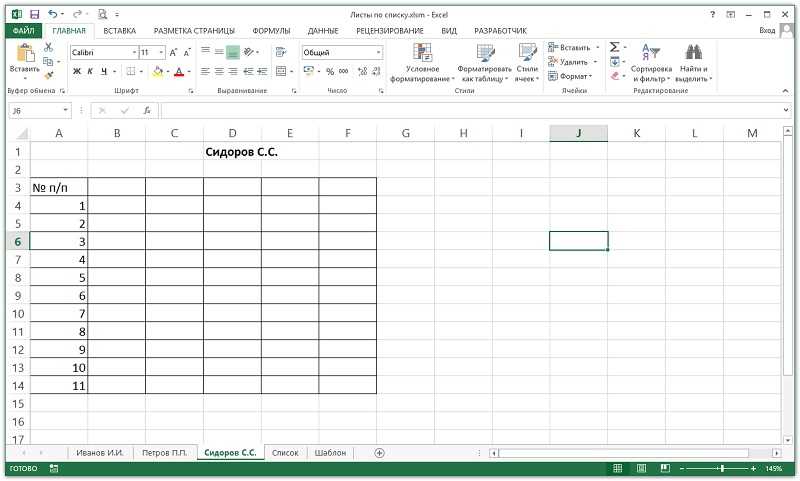
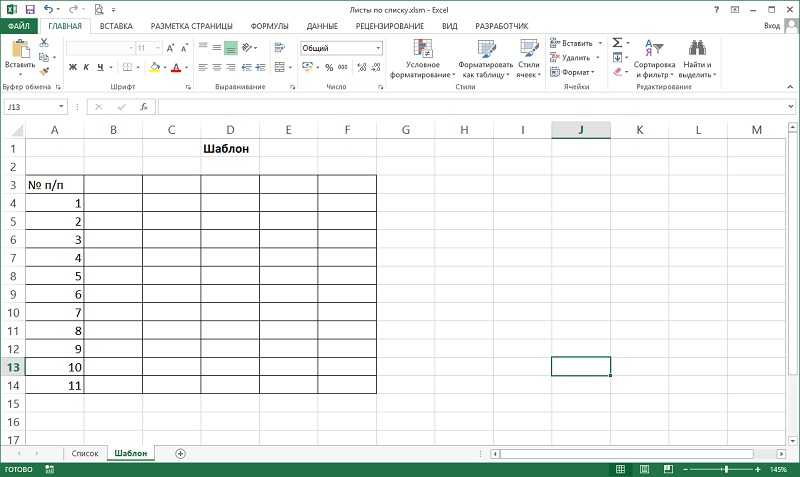
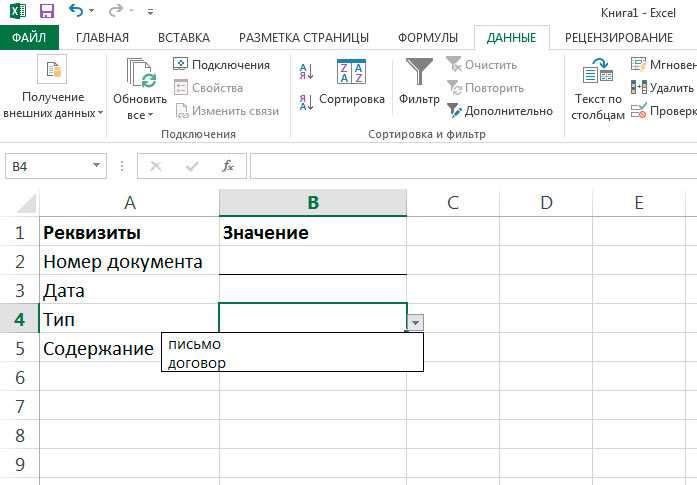
Как в Excel сделать выпадающий список в ячейке с выбором нескольких значений?
Прежде всего, нужно заполнить таблицу. Выделить ее содержимое, и с помощью «Проверки данных» выполнить вышеописанные действия.
Чтобы добавить макрос, кликнуть правой кнопкой мыши по ярлыку листа с выпадающим перечнем и выбрать вариант «Исходный текст». Откроется Visual Basic, в окне редактора следует использовать код для горизонтального отображения:
В результате должно получиться следующее:
Для вертикального отображения можно воспользоваться кодом:
В результате получится так:
Для того чтобы элементы накапливались в той же самой ячейке, подойдет код:
Результат будет таким:





