Содержание:
Обработка данных исследований — непростая задача, необходимо учитывать методы проверки достоверности данных. Прочитав эту статью, мы гарантируем, что расчет исследований с использованием методики парных двух выборочных значений T-критерия будет проще и надежнее.
Раньше для тех, кто не понимал, что такое парный двухвыборочный средний T-тест, парный двухвыборочный средний T-тест представлял собой метод обработки данных на основе SPSS, но его обычно было проще использовать для сравнения двух ответов на один и тот же вопрос. . Например, исследователи рассчитают, может ли игра оказать положительное или отрицательное влияние на респондентов, а затем рассчитают вязкость крови, измеренную с помощью различных инструментов, первое измерение — с помощью стетоскопа, а второе — с помощью динамапы.
Перед обработкой данных убедитесь, что вопросники до и после тестирования соответствуют правилам и связаны с гипотезой о том, что результаты должны быть получены. Задайте тот же вопрос, задав несколько вариантов одного и того же ответа, чтобы провести сравнение.
![]()
Формула ручного расчета:
- Рассчитайте разницу (at = Yi-Xi) между двумя наблюдениями в каждой паре.
- Учет различий d
- Учесть стандартное отклонение разницы в Sd, и использовать его для расчета, средняя ошибка означает
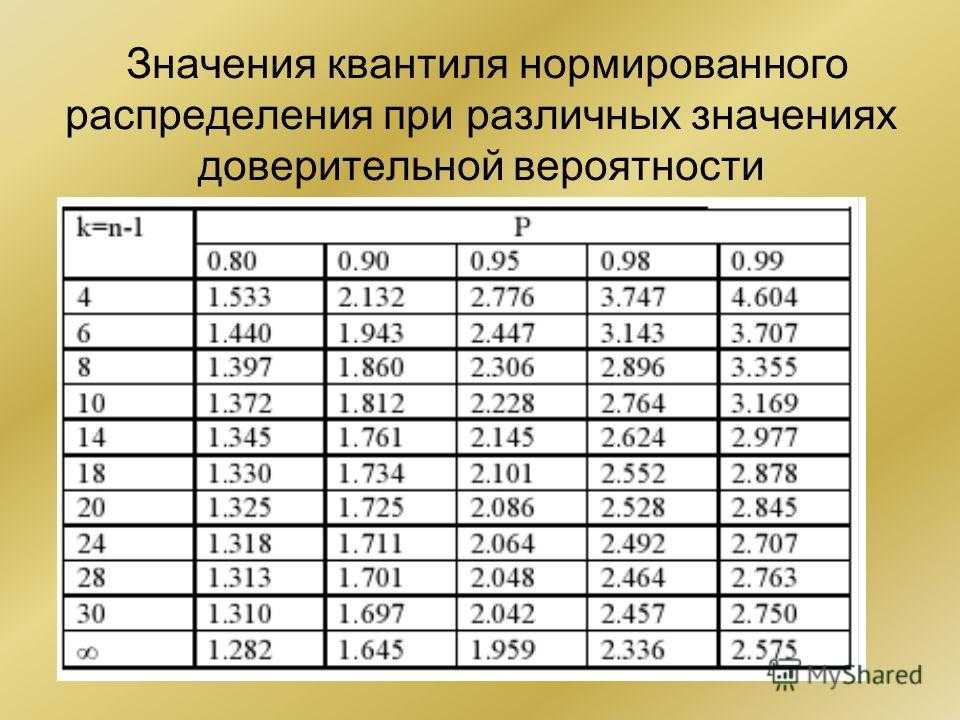
- Рассчитайте T-статистику из это пространство H0 будет сжиматься с t-распределением с п-1 степень свободы.
- Используйте таблицу t-распределения для сравнения значений T с tп-1 Создает p-значение для парного t-критерия.
Пример кейса:
Исследователь рассчитает изменение оценки респондента по результатам теста без учебных модулей, а затем по тесту по учебным модулям.
H1: модуль способен повышать знания.
H0: модуль не может увеличивать знания.
Следующие данные будут обработаны
Затем установите его в своем excel, если нет анализа данных
- Файл-> Параметры-> Надстройки-> Перейти
- Выберите Data Analiys ToolPack
- В ПОРЯДКЕ
![]()
Начать подсчет данных
- Данные-> Анализ данных
![]()
- Выберите t-Test Parired Two Sample Means-> ok
![]()
- Переменная 1 Диапазон содержания балла 1 от респондентов от 1 до 20
- Переменная 2 Диапазон баллов заполнения 2 от 1 до 20 респондентов
- Диапазон вывода заполняется в пустом столбце.
![]()
Вот результаты парного t-теста двух выборочных средних.
![]()
Видно, что T-stat меньше, чем T-критический двух плиток, поэтому можно сделать вывод, что H1 является приемлемым. Модули способны увеличивать знания. Это учебное пособие по расчету парных двух образцов T-теста с использованием Excel.
Безмолвный Artdias
Информационная система Игровые технологии UNIKA SOEGIJAPRANATA
Стипендиаты Министерства образования и культуры (КЕМЕНДИКБУД)
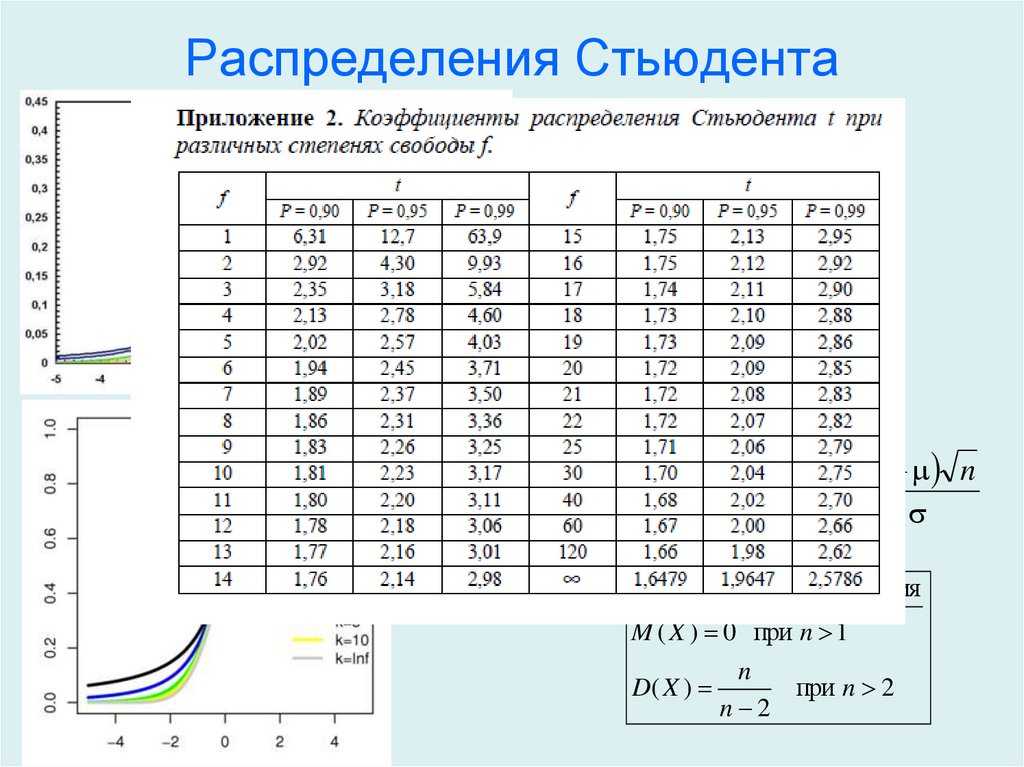
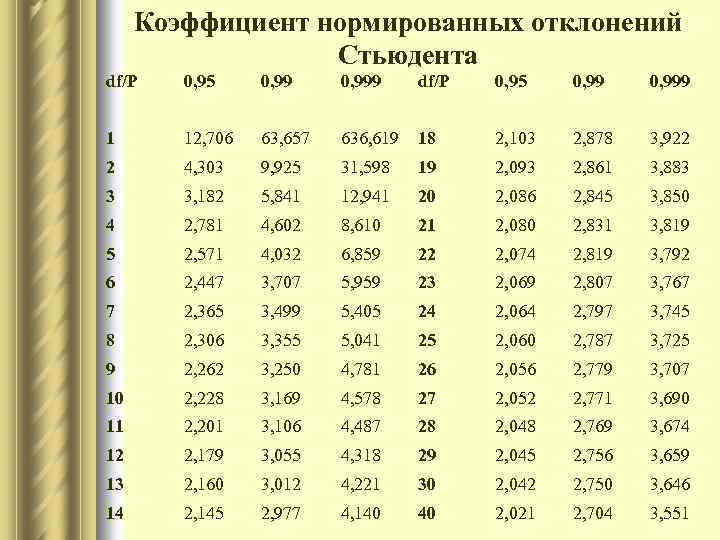
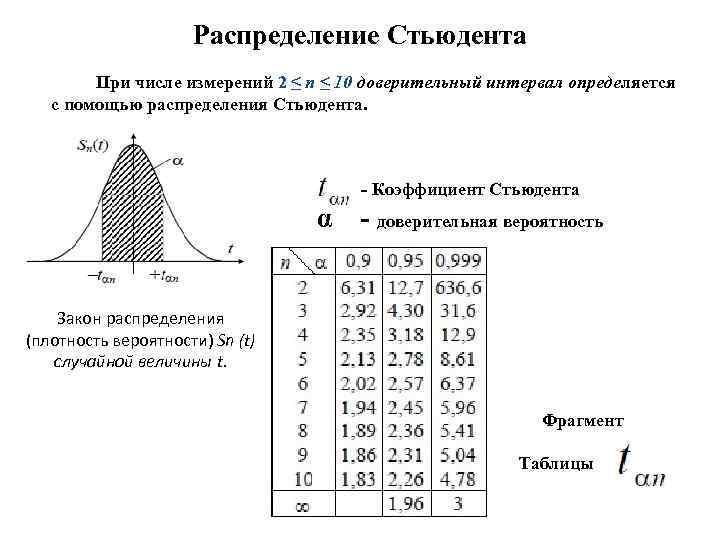
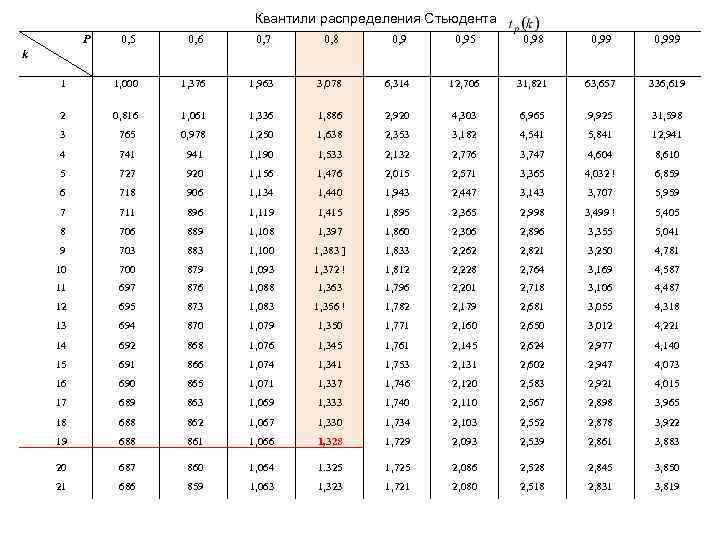
Распределение Стьюдента и нормальное распределение в Excel
Рассматриваемая функция возвращает значение t, соответствующее условию P(|x|>t)=p. Здесь x является значением некоторой случайной величины с распределением Стьюдента, у которого число степеней свобод соответствует k (второй аргумент функции СТЮДРАСПОБР).
Примечания:
- Распределение Стьюдента является одним из видов распределения случайной величины, близкое к нормальному распределению с характерным отличием – сниженная концентрацией отклонений в средней части распределения. Иное название – t-распределение.
- Квантилем считается некоторое значение, которое с определенной вероятностью (фиксированной) не будет превышено случайной величиной.
- Функция СТЮДРАСПОБР считается устаревшей начиная с версии MS Office 2010. Она оставлена для обеспечения совместимости с другими табличными редакторами и документами, созданными в более старых версиях табличного редактора. В новых версиях следует использовать усовершенствованные аналоги: СТЬЮДЕНТ.ОБР.2Х или СТЬЮДЕНТ.ОБР.
Сложение / вычитание времени в Excel
До сих пор мы видели примеры, в которых у нас было время начала и время окончания, и нам нужно было найти разницу во времени.
Excel также позволяет легко добавлять или вычитать фиксированное значение времени из существующего значения даты и времени.
Например, предположим, что у вас есть список задач в очереди, где каждая задача занимает определенное время, и вы хотите знать, когда каждая задача закончится.
В таком случае вы можете легко добавить время, которое займет каждая задача, к времени начала, чтобы узнать, в какое время задача должна быть завершена.
Поскольку Excel хранит значения даты и времени в виде чисел, вы должны убедиться, что время, которое вы пытаетесь добавить, соответствует формату, которому уже следует Excel.
Например, если вы добавите 1 к дате в Excel, это даст вам следующую дату. Это потому, что 1 представляет в Excel целый день (который равен 24 часам).





Поэтому, если вы хотите добавить 1 час к существующему значению времени, вы не можете просто добавить 1 к нему. вы должны убедиться, что вы преобразовали это значение часа в десятичную часть, представляющую один час. то же самое касается добавления минут и секунд.
Использование функции ВРЕМЯ
Функция времени в Excel принимает значение часа, минут и секунд и преобразует их в десятичное число, представляющее это время.
Например, если я хочу добавить 4 часа к существующему времени, я могу использовать следующую формулу:
= Время начала + ВРЕМЯ (4,0,0)
Это полезно, если вы знаете, сколько часов, минут и секунд вы хотите добавить к существующему времени, и просто используете функцию ВРЕМЯ, не беспокоясь о правильном преобразовании времени в десятичное значение.
Также обратите внимание, что функция ВРЕМЯ будет учитывать только целую часть введенного вами значения часа, минуты и секунды. Например, если я использую 5,5 часов в функции ВРЕМЯ, это добавит только пять часов и проигнорирует десятичную часть
Также обратите внимание, что функция ВРЕМЯ может добавлять только значения менее 24 часов. Если значение вашего часа больше 24, это даст вам неверный результат
То же самое касается минут и второй части, где функция будет учитывать только значения, которые меньше 60 минут и 60 секунд.
Так же, как я добавил время с помощью функции ВРЕМЯ, вы также можете вычесть время. Просто измените знак + на отрицательный в приведенных выше формулах.
Использование базовой арифметики
Когда функция времени проста и удобна в использовании, она имеет несколько ограничений (как описано выше).
Если вам нужен больший контроль, вы можете использовать арифметический метод, о котором я расскажу здесь.
Идея проста — преобразуйте значение времени в десятичное значение, которое представляет часть дня, а затем вы можете добавить его к любому значению времени в Excel.
Например, если вы хотите добавить 24 часа к существующему значению времени, вы можете использовать следующую формулу:
= Start_time + 24/24
Это просто означает, что я добавляю один день к существующей временной стоимости.
Теперь, используя ту же концепцию, предположим, что вы хотите добавить 30 часов к значению времени, вы можете использовать следующую формулу:
= Start_time + 30/24
Вышеупомянутая формула делает то же самое, где целая часть (30/24) будет представлять общее количество дней во времени, которое вы хотите добавить, а десятичная часть будет представлять часы / минуты / секунды.
Точно так же, если у вас есть определенное количество минут, которое вы хотите добавить к значению времени, вы можете использовать следующую формулу:
= Start_time + (Минуты для добавления) / 24 * 60
И если у вас есть количество секунд, которое вы хотите добавить, вы можете использовать следующую формулу:
= Start_time + (добавляемые минуты) / 24 * 60 * 60
Хотя этот метод не так прост, как использование функции времени, я считаю его намного лучше, поскольку он работает во всех ситуациях и следует той же концепции. в отличие от функции времени, вам не нужно беспокоиться о том, будет ли время, которое вы хотите добавить, меньше 24 часов или больше 24 часов
Вы можете следовать той же концепции, вычитая время. Просто измените знак + на отрицательный в формулах выше.
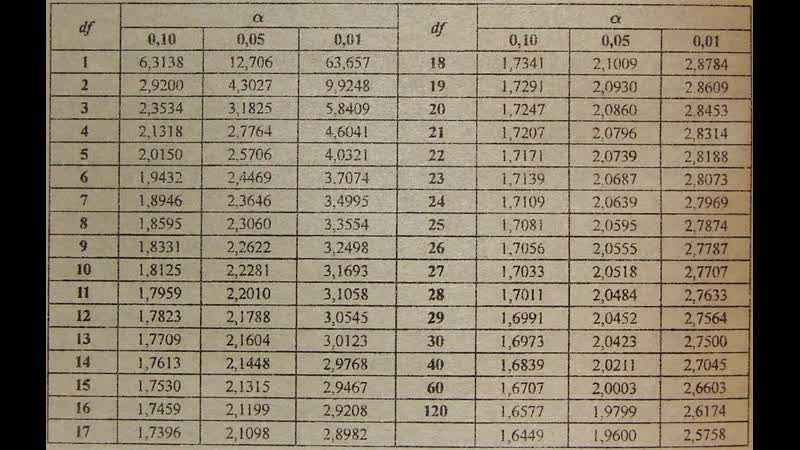
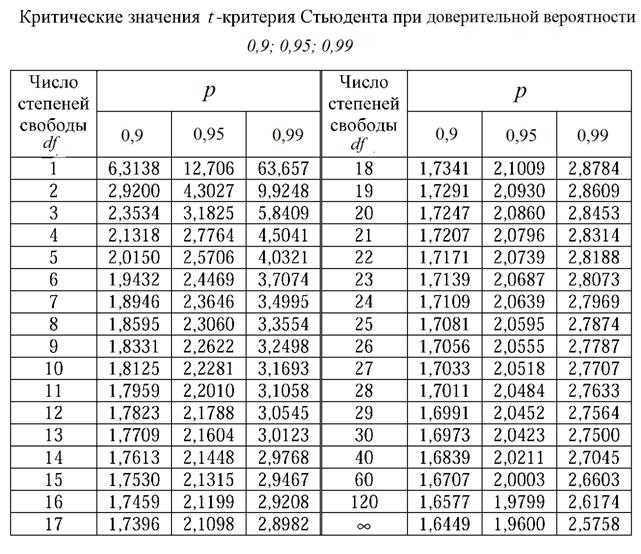
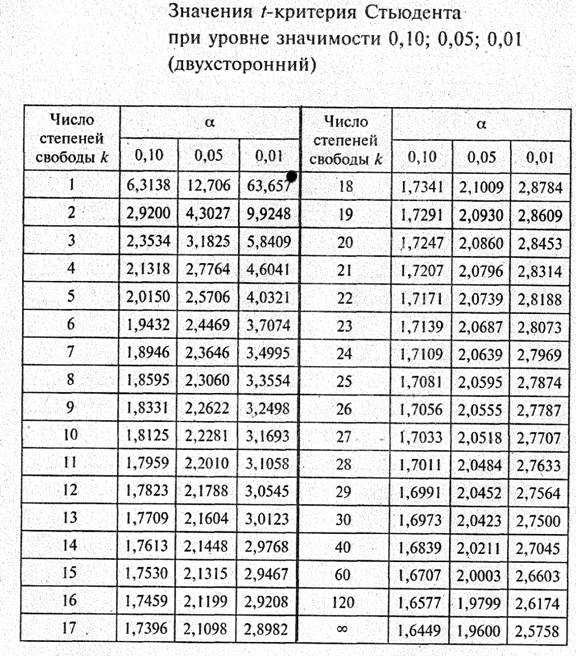
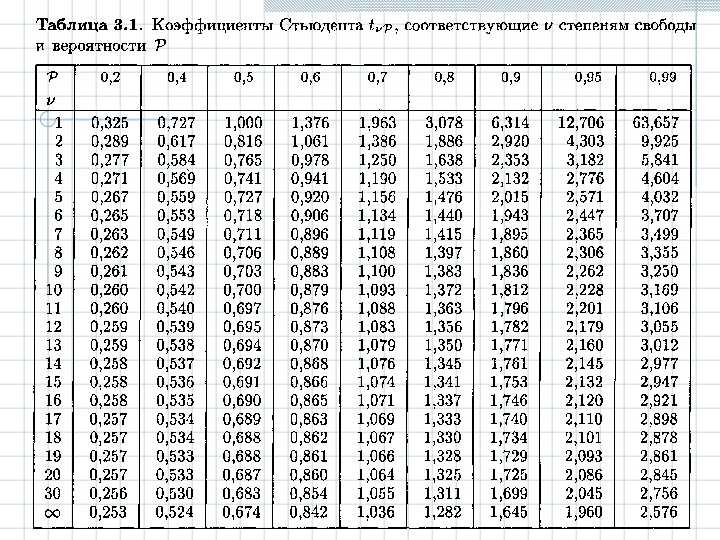
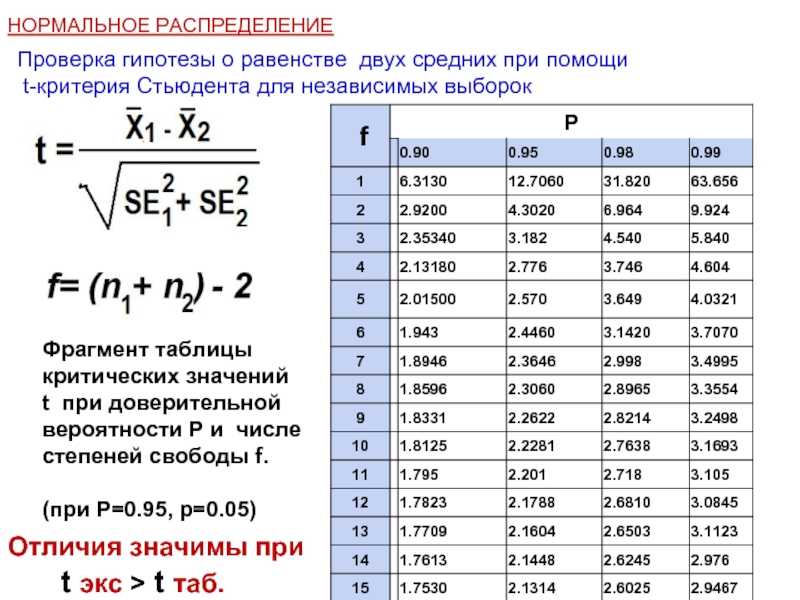
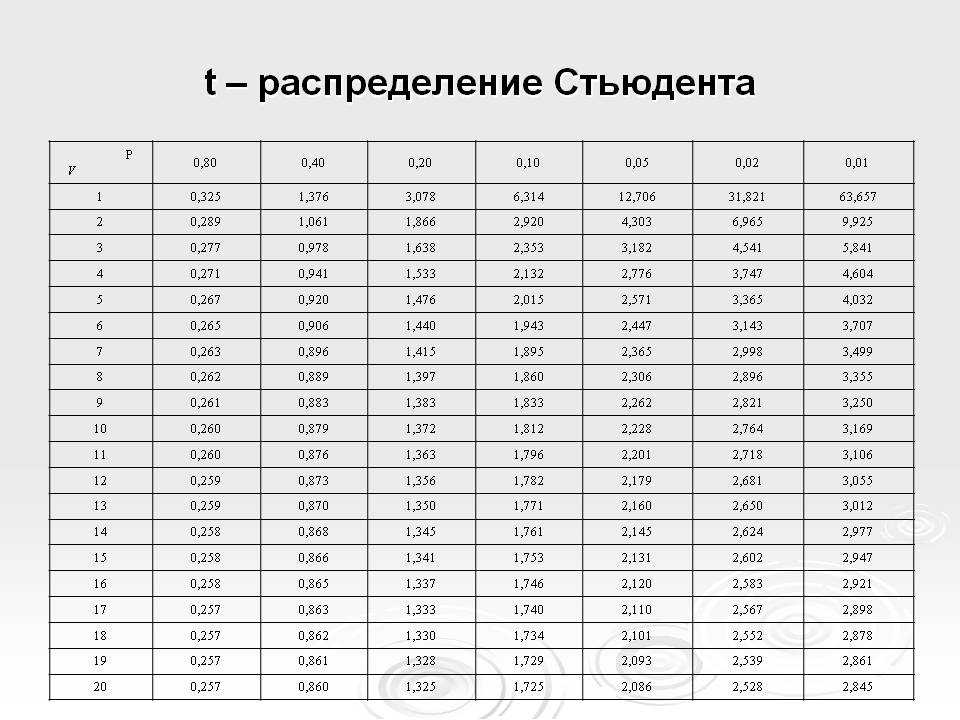
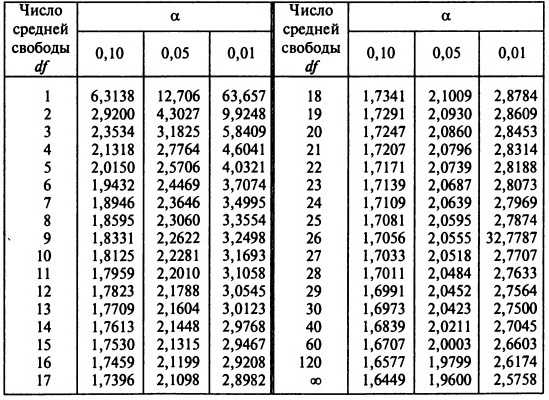
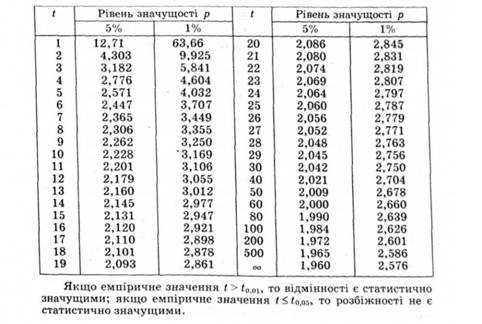
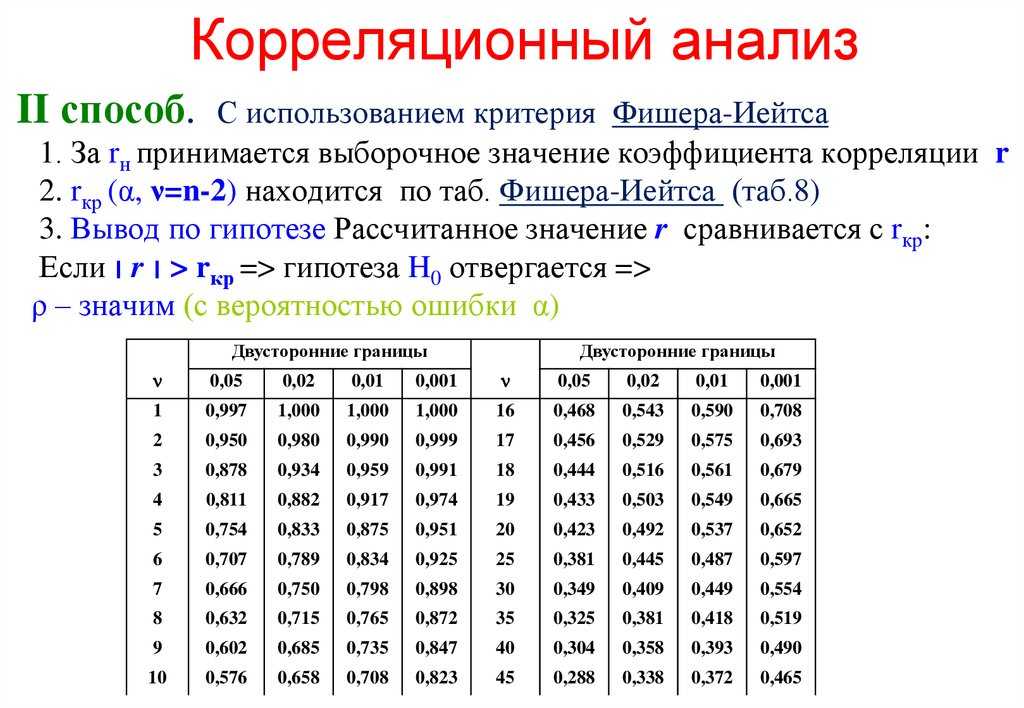
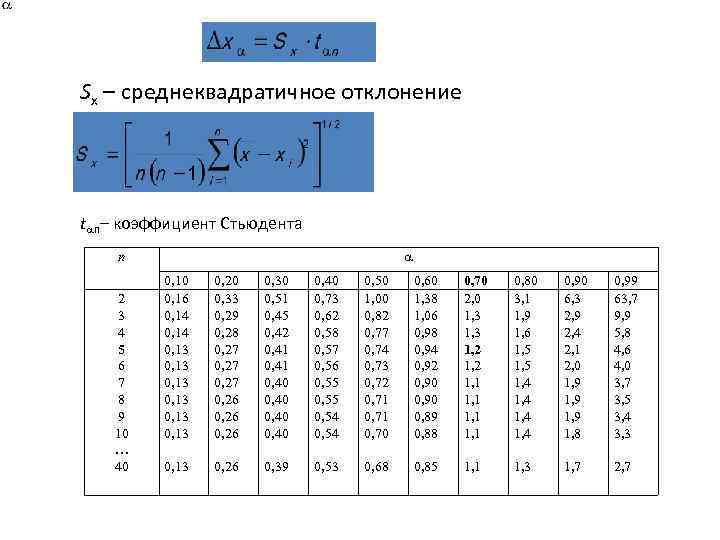
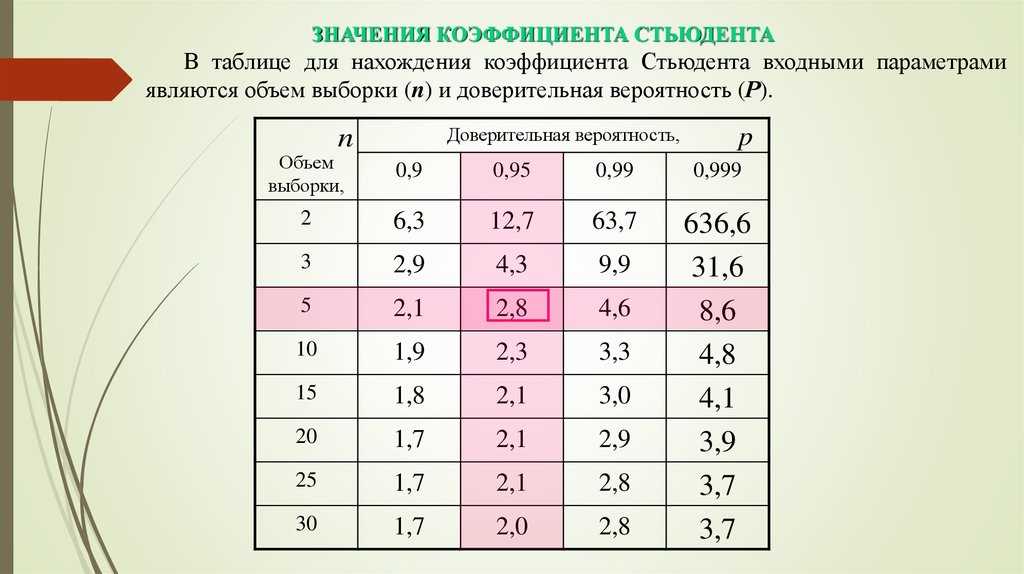
Условия применения t-критерия Стьюдента
Несмотря на то, что открытие Стьюдента в свое время совершило переворот в статистике, t-критерий все же довольно сильно ограничен в возможностях применения, т.к. сам по себе происходит из предположения о нормальном распределении исходных данных. Если данные не являются нормальными (что обычно и бывает), то и t-критерий уже не будет иметь распределения Стьюдента. Однако в силу действия центральной предельной теоремы средняя даже у ненормальных данных быстро приобретает колоколообразную форму распределения.
Рассмотрим, для примера, данные, имеющие выраженный скос вправо, как у распределения хи-квадрат с 5-ю степенями свободы.
![]()
Теперь создадим 20 тысяч выборок и будет наблюдать, как меняется распределение средних в зависимости от их объема.
![]()
Отличие довольно заметно в малых выборках до 15-20-ти наблюдений. Но дальше оно стремительно исчезает. Таким образом, ненормальность распределения – это, конечно, нехорошо, но некритично.


Больше всего t-критерий «боится» выбросов, т.е. аномальных отклонений. Возьмем 20 тыс. нормальных выборок по 15 наблюдений и в часть из них добавим по одному случайном выбросу.
![]()
Картина получается нерадостная. Фактические частоты средних сильно отличаются от теоретических. Использование t-распределения в такой ситуации становится весьма рискованной затеей.
Итак, в не очень малых выборках (от 15-ти наблюдений) t-критерий относительно устойчив к ненормальному распределению исходных данных. А вот выбросы в данных сильно искажают распределение t-критерия, что, в свою очередь, может привести к ошибкам статистического вывода, поэтому от аномальных наблюдений следует избавиться. Часто из выборки удаляют все значения, выходящие за пределы ±2 стандартных отклонения от средней.
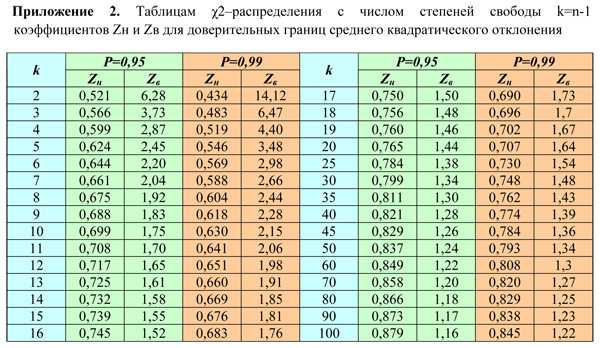
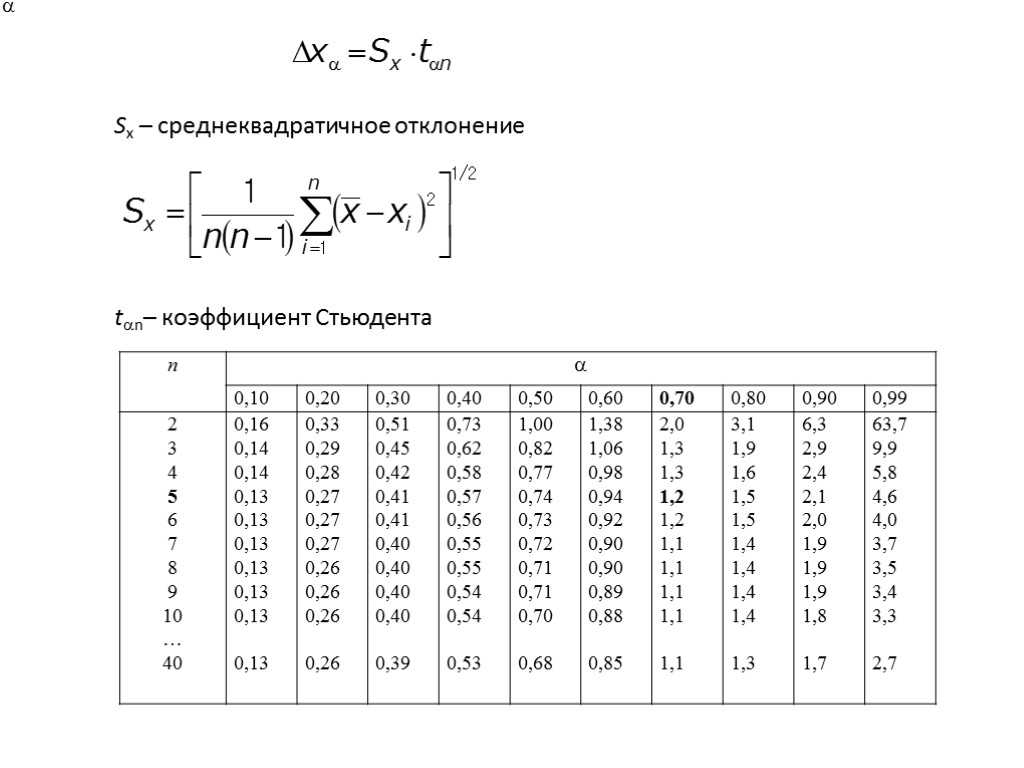
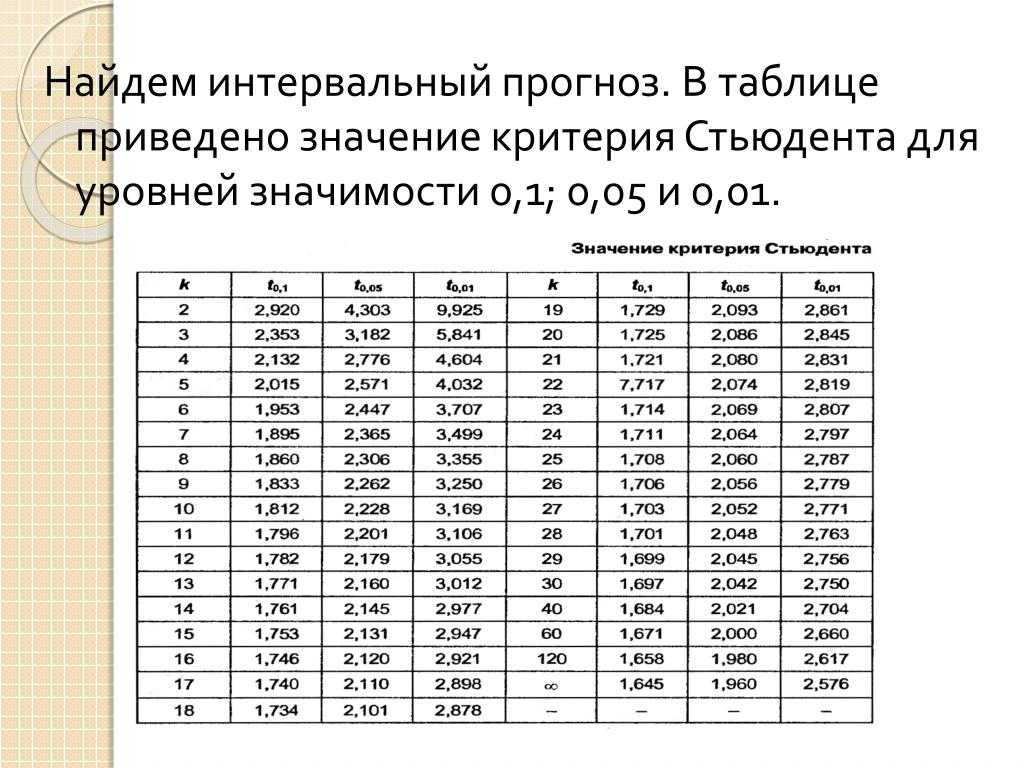
Расчет доверительного интервала для математического ожидания с помощью t-распределения Стьюдента в Excel
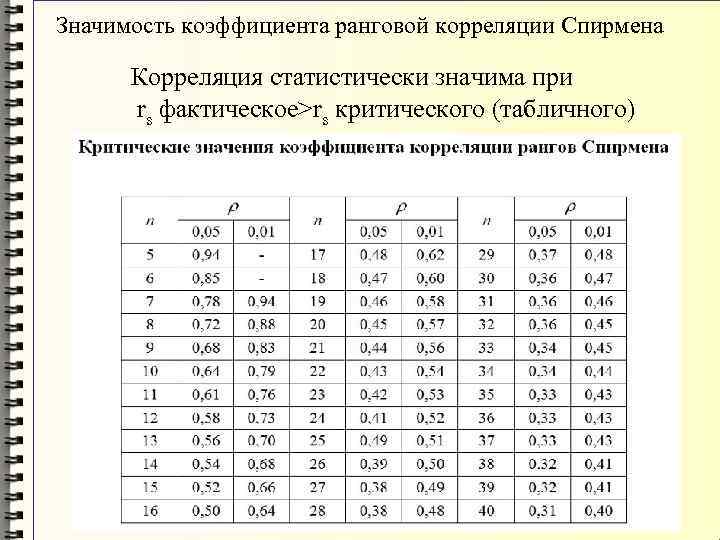
С проверкой гипотез тесно связан еще один статистический метод – расчет доверительных интервалов. Если в полученный интервал попадает значение, соответствующее нулевой гипотезе, то это равносильно тому, что нулевая гипотеза не отклоняется. В противном случае, гипотеза отклоняется с соответствующей доверительной вероятностью. В некоторых случаях аналитики вообще не проверяют гипотез в классическом виде, а рассчитывают только доверительные интервалы. Такой подход позволяет извлечь еще больше полезной информации.
Рассчитаем доверительные интервалы для средней при 9 и 25 наблюдениях. Для этого воспользуемся функцией Excel ДОВЕРИТ.СТЬЮДЕНТ. Здесь, как ни странно, все довольно просто. В аргументах функции нужно указать только уровень значимости α, стандартное отклонение по выборке и размер выборки. На выходе получим полуширину доверительного интервала, то есть значение которое нужно отложить по обе стороны от средней. Проведя расчеты и нарисовав наглядную диаграмму, получим следующее.
Как видно, при выборке в 9 наблюдений значение 50 попадает в доверительный интервал (гипотеза не отклоняется), а при 25-ти наблюдениях не попадает (гипотеза отклоняется). При этом в эксперименте с 25-ю мешками можно утверждать, что с вероятностью 97,5% генеральная средняя превышает 50,1 кг (нижняя граница доверительного интервала равна 50,094кг). А это довольно ценная информация.
Таким образом, мы решили одну и ту же задачу тремя способами:
1. Древним подходом, сравнивая расчетное и табличное значение t-критерия2. Более современным, рассчитав p-value, добавив степень уверенности при отклонении гипотезы.3. Еще более информативным, рассчитав доверительный интервал и получив минимальное значение генеральной средней.
Важно помнить, что t-критерий относится к параметрическим методам, т.к. основан на нормальном распределении (у него два параметра: среднее и дисперсия)
Поэтому для его успешного применения важна хотя бы приблизительная нормальность исходных данных и отсутствие выбросов.
Напоследок предлагаю видеоролик о том, как рассчитать критерий Стьюдента и проверить гипотезу о генеральной средней в Excel.
https://youtube.com/watch?v=MeYSl4f9fSo
Иногда просят объяснить, как делаются такие наглядные диаграммы с распределением. Ниже можно скачать файл, где проводились расчеты для этой статьи.
Всего доброго, будьте здоровы.
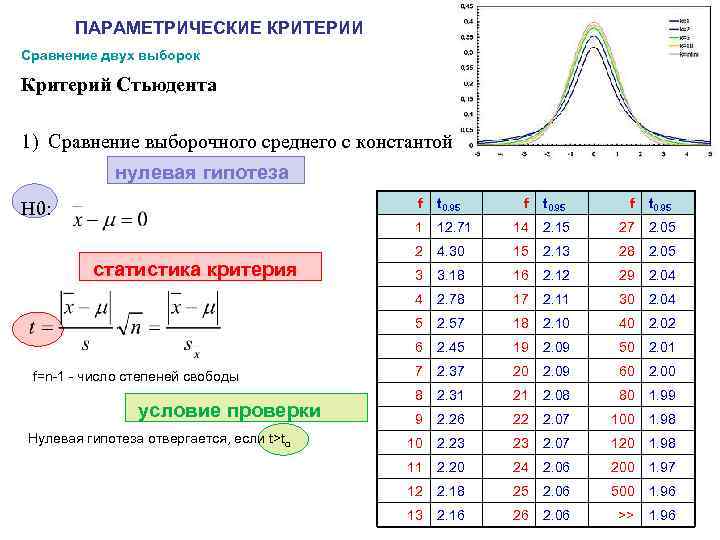
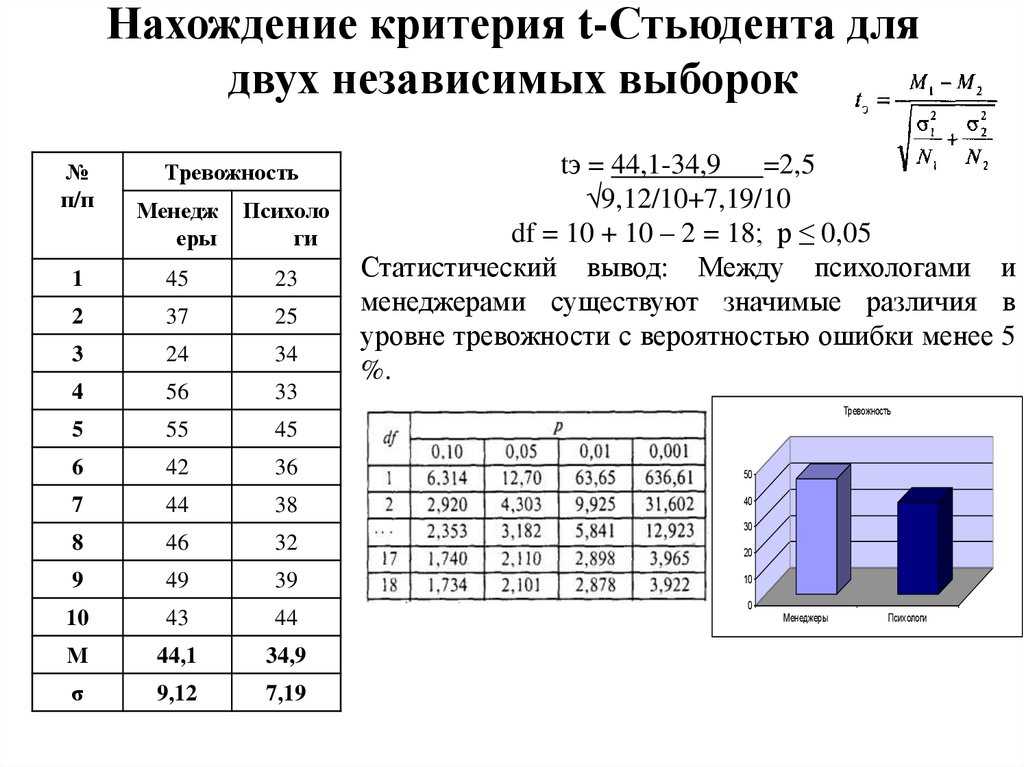
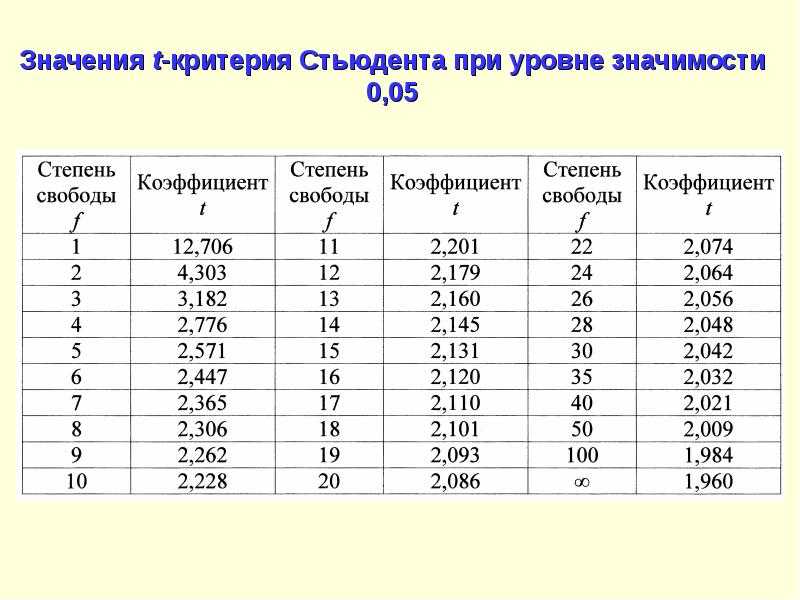
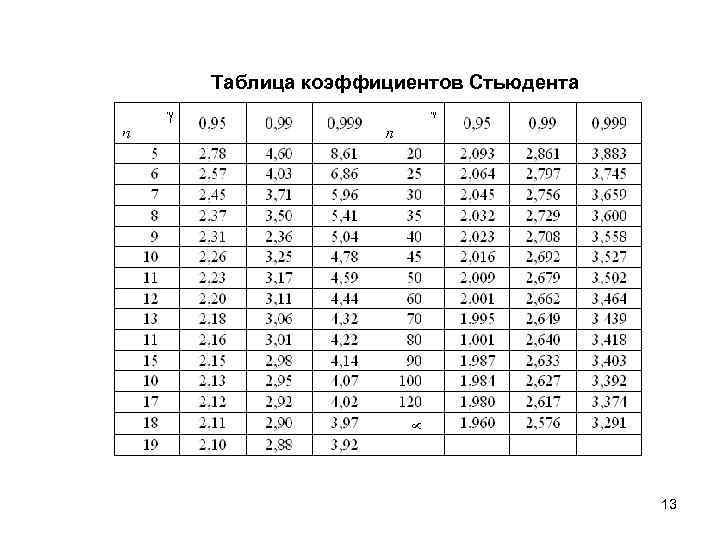
Расчет t-критерия Стьюдента
Для того, чтобы выполнить соответствующие расчеты, понадобится функция “СТЬЮДЕНТ.ТЕСТ”, в ранних версиях Excel (2007 и старше) – “ТТЕСТ”, которая есть и в современных редакциях для сохранения совместимости со старыми документам.
Использовать функцию можно по-разному. Давайте разберем каждый вариант отдельно на примере таблицы с двумя рядами-столбцами числовых значений.
![]()
Метод 1: пользуемся Мастером функций
Этот способ хорош тем, что не нужно запоминать формулу функции (список ее аргументов). Итак, алгоритм действий следующий:
- Встаем в любую свободную ячейку, затем щелкаем по значку “Вставить функцию” слева от строки формул.
- В открывшемся окне Мастера функций выбираем категорию “Полный алфавитный перечень”, в списке ниже находим оператор “СТЬЮДЕНТ.ТЕСТ”, отмечаем его и щелкаем OK.
- На экране отобразится окно, в котором заполняем аргументы функции, после чего нажимаем OK:
- “Массив1” и “Массив2” – указываем диапазоны ячеек, содержащие ряды чисел (в нашем случае это “A2:A7” и “B2:B7”). Мы можем сделать это вручную, введя координаты с клавиатуры, или просто выделяем нужные элементы в самой таблице.
- “Хвосты” – пишем цифру “1”, если требуется выполнить расчет методом одностороннего распределения, или “2” – для двухстороннего.
- “Тип” – в этом поле указываем: “1” – если выборка состоит из зависимых величин; “2” – из независимых; “3” – из независимых величин с неравным отклонением.
- В результате в нашей ячейке с функцией появится рассчитанное значение критерия.
Метод 2: вставляем функцию через “Формулы”
- Переключаемся во вкладку “Формулы”, где также представлена кнопка “Вставить функцию”, которая нам и нужна.
- В результате откроется Мастер функций, дальнейшие действия в котором аналогичны описанным выше.
Через вкладку “Формулы” функцию “СТЬЮДЕНТ.ТЕСТ” можно запустить по-другому:
- В группе инструментов “Библиотека функций” жмем по значку “Другие функции”, после чего раскроется список, в котором выбираем раздел “Статистические”. Пролистав предложенный перечень мы сможем найти нужный нам оператор.
- На экране отобразится окно для заполнения аргументов, с которым мы уже познакомились ранее.
Метод 3: ручной ввод формулы
Опытные пользователи могут обходиться без Мастера функций и в требуемой ячейке сразу вводить формулу со ссылками на нужные диапазоны данных и прочими параметрами. Синтаксис функции в общем виде выглядит так:
= СТЬЮДЕНТ.ТЕСТ(Массив1;Массив2;Хвосты;Тип)
![]()
Каждый из аргументов мы разобрали в первом разделе публикации. Все, что остается сделать после набора формулы – нажать Enter для выполнения расчета.






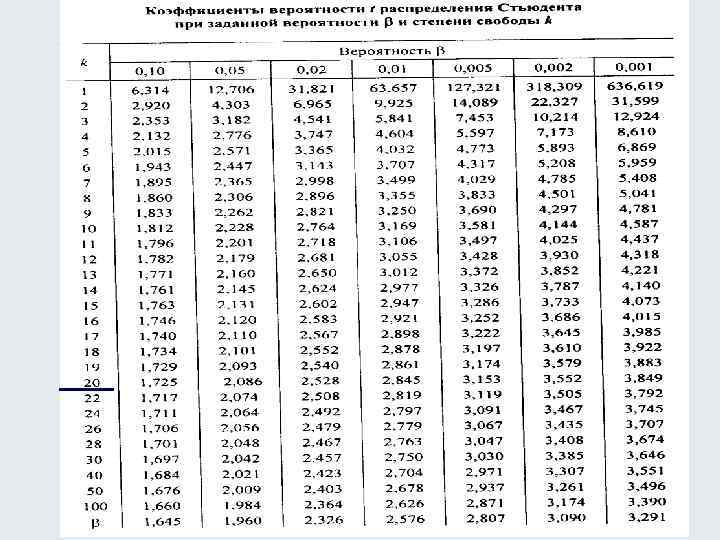
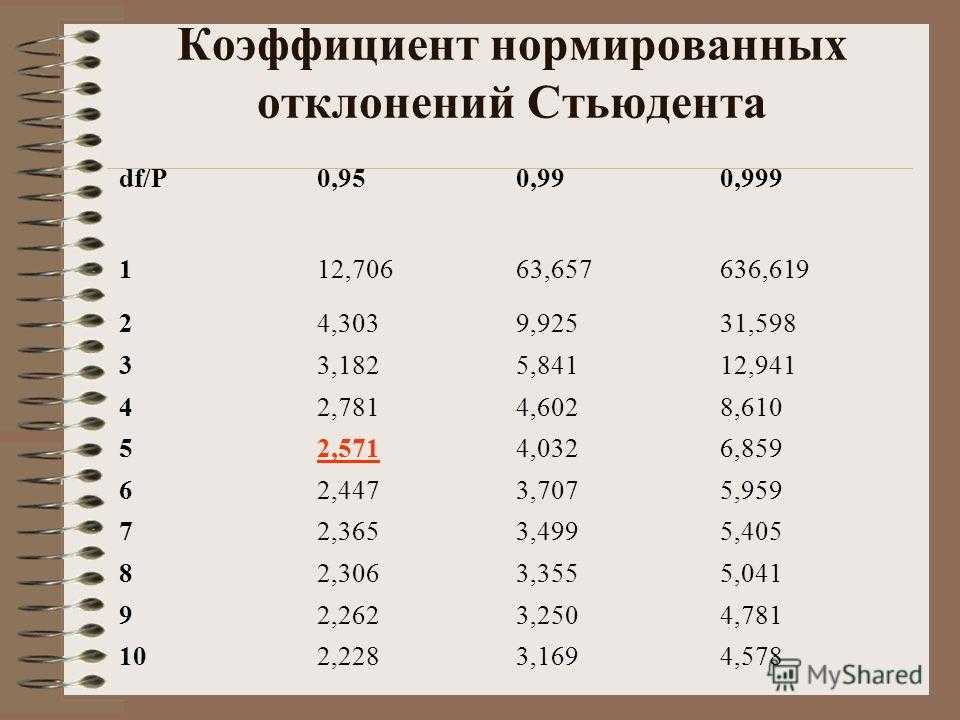
Число степеней свободы в распределении Стьюдента
Пример 2. Сгенерировать 8 случайных чисел с использованием функции СЛЧИС, для которых распределение Стьюдента имеет 4 степени свободы.
Поскольку вероятность того, что случайна величина примет как отрицательное, так и положительное значение является одинаковой и равна 0,5 (распределение Стьюдента симметрично относительно вертикальной оси графика), используем функцию ЕСЛИ для проверки значений.
Выделим 8 ячеек и запишем следующую функцию (вводить как формулу массива CTRL+SHIFT+Enter):
То есть, если случайное значение вероятности, сгенерированное функцией СЛЧИС меньше 0,5, будет сгенерировано отрицательное t-значение, иначе – положительное.
![]()
14.2 Двухвыборочный t-тест
Одна из наиболее часто встречающихся задач при анализе данных — это сравнение средних двух выборок. Для этого нам тоже понадобится t-тест, но теперь \(H_0\) нужно сформулировать по-другому: что две генеральные совокупности (из которых взяты соответствующие выборки) имеют одинаковое среднее.
\
Ну а альтернативная гипотеза, что эти две выборки взяты из распределений с разным средним в генеральной совокупности.
\
Есть две разновидности двухвыборочного t-теста: зависимый t-тест и независимый t-тест. Различие между зависимыми и независимыми тестами принципиальное, мы с ним еще будем сталкиваться.
Зависимые тесты предполагают, что каждому значению в одной выборке мы можем поставить соответствующее значение из другой выборки. Обычно это повторные измерения какого-либо признака в разные моменты времени. В независимых тестах нет возможности сопоставить одно значение с другим. Мы уже не можем напрямую соотнести значения в двух выборках друг с другом, более того, размер двух выборок может быть разным!
Использование зависимых и независимых тестов связано с использованием внутрииндивидуального и межиндивидуального экспериментальных дизайнов в планировании научных экспериментов. Даже если вы не планируете в дальнейшем заниматься проведением экспериментов, понимание различий между двумя видами дизайнов поможет вам понять разницу между зависимыми и независимыми тестами.
Например, мы хотим исследовать влияние кофеина на скорость реакции. Можно поступить по-разному:
-
Набрать выборку, каждому испытуемому дать либо кофеин (например, в виде раствора небольшого количества кофеина в воде), либо обычную воду. Что именно получит испытуемый получит определяется случайным образом. Испытуемый не должен знать, что ему дают (слепое тестирование), а в идеале этого должен не знать даже экспериментатор, который дает напиток и измеряет показатели (двойное слепое тестирование). Посчитать скорость выполнения выбранной задачи, отправить домой. Это межинидивидуальный экспериментальный дизайн, для анализа результатов которого нам понадобится независимый t-тест.
-
Набрать выборку, каждому испытуемому дать и обычную воду, и воду с кофеином, записывать скорость решения задач после употребления простой воды и после употребления воды с кофеином, соответственно. В данном случае будет случайным образом варьироваться порядок предъявления: одни испытуемые сначала получат обычную воду, а потом воду с кофеином, другие испытуемые — наоборот. Для такого эксперимента понадобится меньше участников, но оно будет дольше для каждого участника. Более того, в этом случае мы учтем межиндивидуальные различия участников: одни участники в среднем решают задачи быстрее других. Это внутриинидивидуальный экспериментальный дизайн, для анализа результатов которого нам понадобится зависимый t-тест.
| Внутрииндивидуальный план | Межиндивидуальный план |
|---|---|
| Зависимый t-тест | Независимый t-тест |
Итак, с тем, когда использовать зависимый, а когда независимый t-тест, более-менее разобрались, давайте опробуем их!
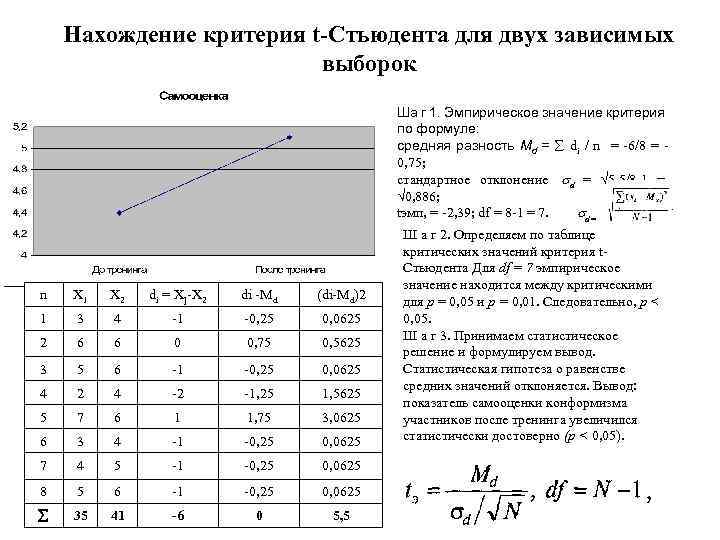
14.2.1 Двухвыборочный зависимый t-тест
Двухвыборочный зависимый t-тест — это то же самое, что и одновыборочный t-тест, только для разницы между связанными значениями. Поскольку наша нулевая гипотеза звучит, что средние должны быть равны,
\
то при верности нулевой гипотезы \.
Тогда вместо \(x\) подставим \(d\) — разницу (вектор разниц) между парами значений. Получаем вот что:
\[t = \frac{\overline{x} — \mu} {s_x / \sqrt{N}} = \frac{\overline{d} — (\mu_1 — \mu_2)} {s_d / \sqrt{N}} = \frac{\overline{d} — 0} {s_d / \sqrt{N}} = \frac{\overline{d}} {s_d / \sqrt{N}}\]
Мы будем использовать данные с курса по статистике Университета Шеффилда про эффективность диет. Мы вытащим оттуда данные по диете номер 1 и посмотрим, действительно ли она помогает сбросить вес.
Провести двухвыборочный t-тест можно в R двумя базовыми способами. Первый вариант — это дать два вектора значений. Это удобно в случае широкого формата данных.
Второй вариант — используя формулы. Это удобно при длинном формате данных:
В обоих вариантах мы использовали , чтобы обозначить использование именно зависимого (т.е. парного) t-теста.
| Внутрииндивидуальный план | Межиндивидуальный план |
|---|---|
| Зависимый t-тест | Независимый t-тест |
Условия применения t-критерия Стьюдента
Несмотря на то, что открытие Стьюдента в свое время совершило переворот в статистике, t-критерий все же довольно сильно ограничен в возможностях применения, т.к. сам по себе происходит из предположения о нормальном распределении исходных данных. Если данные не являются нормальными (что обычно и бывает), то и t-критерий уже не будет иметь распределения Стьюдента. Однако в силу действия центральной предельной теоремы средняя даже у ненормальных данных быстро приобретает колоколообразную форму распределения.
Рассмотрим, для примера, данные, имеющие выраженный скос вправо, как у распределения хи-квадрат с 5-ю степенями свободы.
Теперь создадим 20 тысяч выборок и будет наблюдать, как меняется распределение средних в зависимости от их объема.
Отличие довольно заметно в малых выборках до 15-20-ти наблюдений. Но дальше оно стремительно исчезает. Таким образом, ненормальность распределения – это, конечно, нехорошо, но некритично.




Больше всего t-критерий «боится» выбросов, т.е. аномальных отклонений. Возьмем 20 тыс. нормальных выборок по 15 наблюдений и в часть из них добавим по одному случайном выбросу.
Картина получается нерадостная. Фактические частоты средних сильно отличаются от теоретических. Использование t-распределения в такой ситуации становится весьма рискованной затеей.
Итак, в не очень малых выборках (от 15-ти наблюдений) t-критерий относительно устойчив к ненормальному распределению исходных данных. А вот выбросы в данных сильно искажают распределение t-критерия, что, в свою очередь, может привести к ошибкам статистического вывода, поэтому от аномальных наблюдений следует избавиться. Часто из выборки удаляют все значения, выходящие за пределы ±2 стандартных отклонения от средней.
Нормальное распределение в статистике
История закона насчитывает 300 лет. Первым открывателем стал Абрахам де Муавр, который придумал аппроксимацию биномиального распределения еще 1733 году. Через много лет Карл Фридрих Гаусс (1809 г.) и Пьер-Симон Лаплас (1812 г.) вывели математические функции.
Лаплас также обнаружил замечательную закономерность и сформулировал центральную предельную теорему (ЦПТ), согласно которой сумма большого количества малых и независимых величин имеет нормальное распределение.
Нормальный закон не является фиксированным уравнением зависимости одной переменной от другой. Фиксируется только характер этой зависимости. Конкретная форма распределения задается специальными параметрами. Например, у = аx + b – это уравнение прямой. Однако где конкретно она проходит и под каким наклоном, определяется параметрами а и b. Также и с нормальным распределением. Ясно, что это функция, которая описывает тенденцию высокой концентрации значений около центра, но ее точная форма задается специальными параметрами.
Кривая нормального распределения Гаусса имеет следующий вид.
График нормального распределения напоминает колокол, поэтому можно встретить название колоколообразная кривая. У графика имеется «горб» в середине и резкое снижение плотности по краям. В этом заключается суть нормального распределения. Вероятность того, что случайная величина окажется около центра гораздо выше, чем то, что она сильно отклонится от середины.
На рисунке выше изображены два участка под кривой Гаусса: синий и зеленый. Основания, т.е. интервалы, у обоих участков равны. Но заметно отличаются высоты. Синий участок удален от центра, и имеет существенно меньшую высоту, чем зеленый, который находится в самом центре распределения. Следовательно, отличаются и площади, то бишь вероятности попадания в обозначенные интервалы.
Формула нормального распределения (плотности) следующая.
Формула состоит из двух математических констант:
π – число пи 3,142;
е – основание натурального логарифма 2,718;
двух изменяемых параметров, которые задают форму конкретной кривой:
m – математическое ожидание (в различных источниках могут использоваться другие обозначения, например, µ или a>);
σ2 – дисперсия;
ну и сама переменная x, для которой высчитывается плотность вероятности.
Конкретная форма нормального распределения зависит от 2-х параметров: математического ожидания (m) и дисперсии (σ2). Кратко обозначается N(m, σ2) или N(m, σ). Параметр m (матожидание) определяет центр распределения, которому соответствует максимальная высота графика. Дисперсия σ2 характеризует размах вариации, то есть «размазанность» данных.
Параметр математического ожидания смещает центр распределения вправо или влево, не влияя на саму форму кривой плотности.
А вот дисперсия определяет остроконечность кривой. Когда данные имеют малый разброс, то вся их масса концентрируется у центра. Если же у данных большой разброс, то они «размазываются» по широкому диапазону.
Плотность распределения не имеет прямого практического применения. Для расчета вероятностей нужно проинтегрировать функцию плотности.






Вероятность того, что случайная величина окажется меньше некоторого значения x, определяется функцией нормального распределения:
P(a ≤ X < b) = Ф(b) – Ф(a)
Условия применения t-критерия Стьюдента
Несмотря на то, что открытие Стьюдента в свое время совершило переворот в статистике, t-критерий все же довольно сильно ограничен в возможностях применения, т.к. сам по себе происходит из предположения о нормальном распределении исходных данных. Если данные не являются нормальными (что обычно и бывает), то и t-критерий уже не будет иметь распределения Стьюдента. Однако в силу действия центральной предельной теоремы средняя даже у ненормальных данных быстро приобретает колоколообразную форму распределения.
Рассмотрим, для примера, данные, имеющие выраженный скос вправо, как у распределения хи-квадрат с 5-ю степенями свободы.
![]()
Теперь создадим 20 тысяч выборок и будет наблюдать, как меняется распределение средних в зависимости от их объема.
![]()
Отличие довольно заметно в малых выборках до 15-20-ти наблюдений. Но дальше оно стремительно исчезает. Таким образом, ненормальность распределения – это, конечно, нехорошо, но некритично.
Больше всего t-критерий «боится» выбросов, т.е. аномальных отклонений. Возьмем 20 тыс. нормальных выборок по 15 наблюдений и в часть из них добавим по одному случайном выбросу.
![]()
Картина получается нерадостная. Фактические частоты средних сильно отличаются от теоретических. Использование t-распределения в такой ситуации становится весьма рискованной затеей.
Итак, в не очень малых выборках (от 15-ти наблюдений) t-критерий относительно устойчив к ненормальному распределению исходных данных. А вот выбросы в данных сильно искажают распределение t-критерия, что, в свою очередь, может привести к ошибкам статистического вывода, поэтому от аномальных наблюдений следует избавиться. Часто из выборки удаляют все значения, выходящие за пределы ±2 стандартных отклонения от средней.





